Ubuntu深度学习环境终极搭建指南:从NVIDIA驱动、CUDA到PyTorch保姆级教程
作者:一位踩过无数坑的AI开发者
适用人群:Linux初学者、深度学习入门者、AI项目部署工程师
更新时间:2025年1月1日
支持系统:Ubuntu 20.04/22.04/24.04(其他Linux发行版可参考)
摘要
在深度学习、机器学习及高性能计算领域,正确配置NVIDIA显卡驱动与CUDA环境是发挥GPU算力的关键第一步。然而,NVIDIA驱动、CUDA、cuDNN与深度学习框架(如PyTorch)之间的版本兼容性问题,常常让初学者陷入困境。
本文旨在提供一份从零开始、保姆级的Ubuntu深度学习环境搭建指南。我们将手把手带你完成硬件检测、驱动安装、CUDA与cuDNN配置、Python环境管理,直至PyTorch的安装与GPU验证。无论你是Linux新手还是希望快速部署项目的工程师,本指南都将助你一次成功,跨越环境配置的门槛。
前言
在进行深度学习、机器学习或高性能计算时,正确配置NVIDIA显卡驱动和CUDA环境是至关重要的。本文将为您提供一个完整的Ubuntu系统下NVIDIA显卡驱动与CUDA环境配置指南,涵盖从显卡识别到PyTorch安装的全流程。
在深度学习项目中,GPU环境配置是每个开发者必须跨越的第一道门槛。然而,NVIDIA驱动、CUDA、cuDNN、PyTorch之间的版本兼容性问题常常让人“从入门到放弃”。
本文将带你从零开始,手把手完成整套深度学习环境的搭建,涵盖硬件检测、驱动安装、CUDA配置、PyTorch验证等完整流程,并提供常见问题解决方案,助你一次成功!
⚠️ 重要提示:开始前请注意
- 数据备份:驱动和内核级别的操作有一定风险,强烈建议备份系统中的重要数据。
- 网络环境:请确保稳定的网络连接,因为需要下载大文件(驱动、CUDA Toolkit等)。
- 物理访问:尽可能在物理机前操作,避免通过SSH远程安装显卡驱动。如果安装失败导致图形界面无法进入,物理访问对于修复至关重要。
- 仔细阅读:请勿盲目复制粘贴命令,务必理解每一步的意义,特别是版本号的选择。
目录
- 环境组件概述
- 硬件检测:识别你的NVIDIA显卡
- 安装NVIDIA显卡驱动
- 安装CUDA Toolkit
- 安装cuDNN
- 管理Python环境并安装Miniconda
- PyTorch安装与GPU验证
- 总结
环境组件概述
在开始配置之前,让我们先了解各个组件的作用和安装顺序:
| 组件名称 | 意义 | 安装顺序 |
|---|---|---|
| 显卡驱动(GPU Driver) | 连接操作系统和GPU硬件的软件程序,管理GPU的基本功能,是所有组件的基础。必须与特定GPU硬件兼容,以确保GPU能够正常工作并与操作系统和应用程序通信 | 1 |
| CUDA (Compute Unified Device Architecture) | NVIDIA开发的并行计算平台和编程模型,用于加速通用计算任务。它允许开发者使用GPU进行高性能的数值计算,包括深度学习训练和推理 | 2 |
| CUDA Toolkit | 包含编译CUDA代码所需的工具、运行时库和数学库,是使用CUDA进行开发的必备工具集 | 3 |
| cuDNN (CUDA Deep Neural Network Library) | NVIDIA的深度学习库,专门用于加速深度神经网络的训练和推理,提升深度学习框架在GPU上的性能 | 4 |
| PyTorch | 深度学习框架,提供构建和训练神经网络的高级API,可与CUDA和cuDNN集成以实现GPU加速 | 5 |
重要概念理解
运行任何CUDA程序都需要两个基本条件:
- 硬件:支持CUDA的显卡
- 软件:与CUDA Toolkit兼容的显卡驱动程序
NVIDIA显卡驱动与CUDA的关系:
- NVIDIA显卡驱动与CUDA并不是一对一对应的关系
- NVIDIA显卡驱动只要满足CUDA版本的最低要求即可
- CUDA程序是向后兼容的,针对特定版本的CUDA编译的应用程序将继续在后续驱动程序版本上工作
版本兼容性: 一般CUDA版本是依赖驱动版本的,相当于驱动给你提供平台,CUDA相当于软件,确定了平台版本,软件版本可随自己设置确定。
注意:CUDA版本与MXNet(一种深度学习框架)版本是一一对应的,不可改变
您可以参考NVIDIA官方文档了解具体的CUDA与驱动版本对应关系:CUDA Toolkit Release Notes
CUDA与驱动版本对照表
| CUDA Toolkit | Linux x86_64 最低驱动版本 | Windows x86_64 最低驱动版本 |
|---|---|---|
| CUDA 12.x | >=525.60.13 | >=528.33 |
| CUDA 11.8.x ~ 11.1.x | >=450.80.02 | >=452.39 |
| CUDA 11.0 (11.0.3) | >=450.36.06 | >=451.22 |
硬件检测—识别你的NVIDIA显卡
在安装驱动之前,首先需要确认系统中是否装有NVIDIA显卡及其型号。
使用nvidia-smi命令
查看系统是否已经安装了NVIDIA驱动,nvidia-smi 是最直接的工具。它能提供详细的GPU信息,包括驱动版本、CUDA版本上限和GPU使用情况。
1 | nvidia-smi |
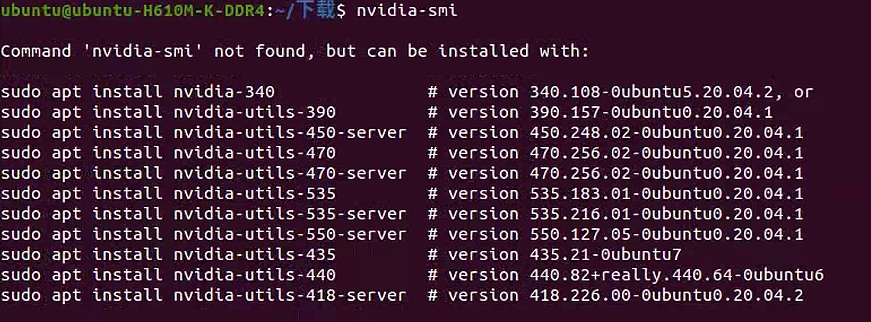
- 如果命令未找到,说明未安装驱动。
- 如果报错
NVIDIA-SMI has failed,可能是驱动未正确加载或Secure Boot问题。
使用lspci命令
运行以下命令检查是否识别到NVIDIA显卡:
1 | lspci | grep -i nvidia |
输出示例:
1 | 01:00.0 VGA compatible controller: NVIDIA Corporation Device 2584 (rev a1) |
Device 2584是你的显卡设备ID,可通过 TechPowerUp GPU Database 查询具体型号(如 RTX 3060)。
lspci命令详解(该部分可跳过)
命令 1: lspci
作用:
- 列出所有 PCI 设备的简要信息。用于查看系统中所有硬件设备的列表。
- PCI(Peripheral Component Interconnect)是一种计算机硬件的局部总线标准,用于连接计算机内部的高速设备,如显卡、声卡等。通过这个命令,可以获取系统中所有通过 PCI 总线连接的设备的详细信息。
示例:
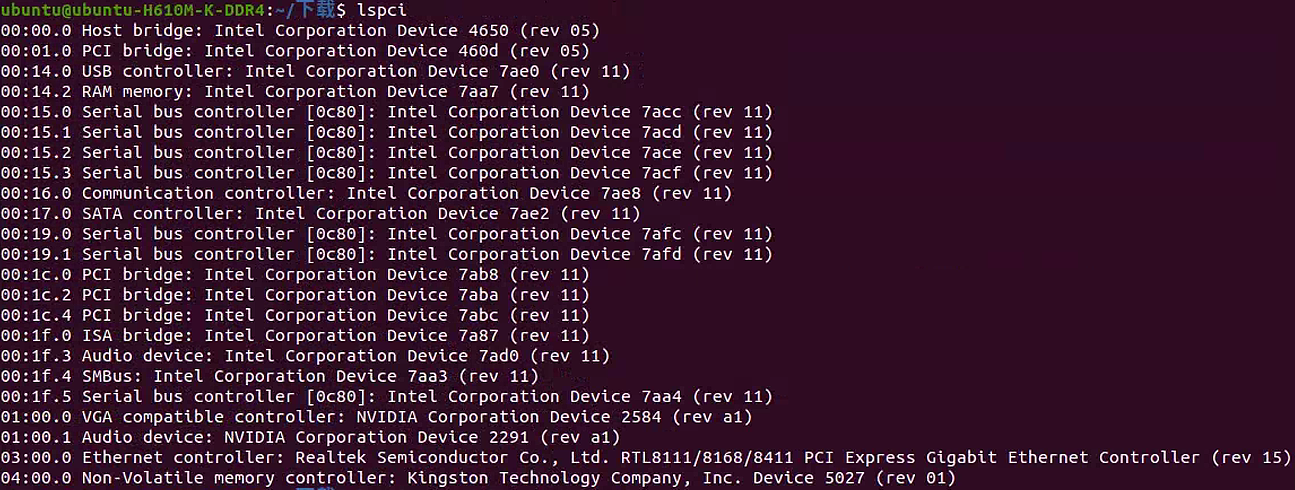
输出:
1 | 00:00.0 Host bridge: Intel Corporation Device 4650 (rev 05) |
| 字段 | 含义 |
|---|---|
Host bridge | 主机桥接器(连接 CPU 和其他设备的核心组件)。 |
PCI bridge | PCI 桥接器,用于扩展 PCI 总线。 |
USB controller | USB 控制器,管理 USB 设备。 |
SATA controller | SATA 控制器,管理硬盘等存储设备。 |
Ethernet controller | 以太网控制器,管理网络接口。 |
Non-Volatile memory controller | NVMe 控制器,管理固态硬盘。 |
命令 2: lspci | grep -i vga
作用:
- 列出所有 PCI 设备,并通过
grep过滤出与 VGA(显卡)相关的设备。 grep -i vga: 不区分大小写(-i)查找包含”vga”的行- |:这是一个管道符号,用于将前一个命令的输出作为后一个命令的输入。lspci 命令的输出结果会被传递给后面的 grep 命令
- grep:这是一个文本搜索命令,用于在文本中搜索符合特定模式的字符串。从 lspci 命令的输出中筛选出包含“VGA”字符串的行
- 用于快速查看系统中安装的显卡信息。
示例:

输出:
1 | 01:00.0 VGA compatible controller: NVIDIA Corporation Device 2584 (rev a1) |
| 字段 | 含义 |
|---|---|
01:00.0 | PCI 设备地址,表示总线号(01)、设备号(00)、功能号(0)。 |
VGA compatible controller | 表示该设备是一个兼容 VGA 的控制器(即显卡)。 |
NVIDIA Corporation | 显卡制造商是 NVIDIA。 |
Device 2584 | 设备 ID,标识具体的硬件型号(2584 是 NVIDIA 的一个显卡设备 ID)。 |
(rev a1) | 硬件修订版本号,表示该设备的硬件版本(a1 是十六进制值)。 |
命令 3: lspci -v | grep -A 10 VGA
作用:
- 列出所有 PCI 设备的详细信息,并过滤出与 VGA 相关的部分,显示其后 10 行的详细信息
-v: 表示详细模式,会显示设备的详细信息,包括设备的名称、型号、制造商等-A 10: 显示匹配行及其后10行- 用于查看显卡的更多技术细节,如内存地址、驱动程序等
示例:
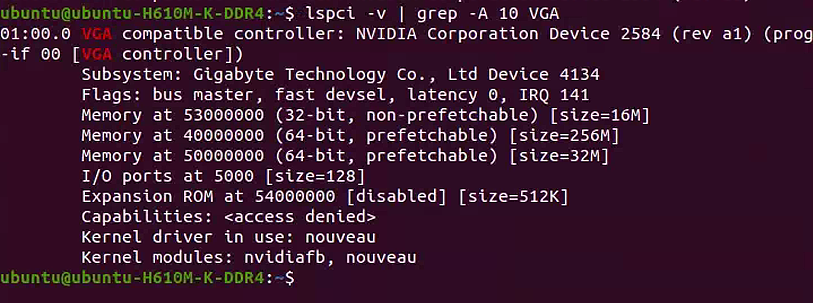
输出:
1 | 01:00.0 VGA compatible controller: NVIDIA Corporation Device 2584 (rev a1) (prog-if 00 [VGA controller]) |
| 字段 | 含义 |
|---|---|
Subsystem | 子系统信息,表示显卡的具体型号或厂商(这里是 Gigabyte 的设备 4134)。 |
Flags | 设备标志,描述设备的功能特性(如是否支持总线主控、延迟时间等)。 |
Memory at ... | 显卡使用的内存地址范围及其大小(用于帧缓冲区等)。 |
I/O ports at ... | 显卡的 I/O 端口地址范围及其大小。 |
Expansion ROM | 扩展 ROM 地址及其状态(这里是禁用状态)。 |
Kernel driver in use | 当前使用的内核驱动程序(这里是开源驱动 nouveau)。 |
Kernel modules | 可用的内核模块(这里是 nvidiafb 和 nouveau)。 |
命令 4: lspci | grep -i nvidia
作用:
- 列出所有 PCI 设备,并过滤出与 NVIDIA 相关的设备。
- 用于查看系统中所有 NVIDIA 设备(包括显卡和音频设备)。
示例:

输出:
1 | 01:00.0 VGA compatible controller: NVIDIA Corporation Device 2584 (rev a1) |
| 字段 | 含义 |
|---|---|
01:00.0 | 显卡设备地址 |
Device 2584 | Device设备号 |
01:00.1 | NVIDIA 显卡附带的音频设备地址(HDMI 音频输出) |
Audio device | 表示这是一个音频设备 |
Device 2291 | 音频设备的设备 ID |
如果输出如下:
01:00.0 3D controller: NVIDIA Corporation GM108M [GeForce 920MX] (rev a2)
其中,GeForce 920MX就是我们的显卡型号。
命令 5: lspci -vnn | grep VGA -A 12
作用:
- 列出所有 PCI 设备的详细信息,并过滤出与 VGA 相关的部分,显示其后 12 行的详细信息。
- -vnn:这是 lspci 命令的选项参数。
- -nn:表示以数值形式显示设备的供应商 ID (Device ID) 和设备 ID (Vendor ID)。供应商 ID 和设备 ID 是用于唯一标识硬件设备的代码,通过这些代码,可以更准确地确定设备的具体型号。
- VGA(Video Graphics Array)是一种视频显示标准,通常用于显卡。在这里,通过搜索“VGA”,可以找到系统中与显卡相关的信息。
- -A 12:这是 grep 命令的选项参数,表示在找到匹配的行后,还会显示该行之后的 12 行内容。这样做的目的是为了获取更多与显卡相关的信息,因为显卡的信息可能分布在多行中,而不仅仅是在包含“VGA”字符串的那一行。
示例:

输出:
1 | 01:00.0 VGA compatible controller [0300]: NVIDIA Corporation Device [10de:2584] (rev a1) (prog-if 00 [VGA controller]) |
| 字段 | 含义 |
|---|---|
[0300] | 类别代码,表示该设备属于 VGA 兼容控制器类别。 |
[10de:2584] | Vendor ID 和 Device ID,唯一标识设备(10DE 是 NVIDIA,2584 是具体型号)。 |
[1458:4134] | 子系统 Vendor ID 和 Device ID(1458 是 Gigabyte,4134 是具体型号)。 |
(prog-if 00 [VGA controller]) | 编程接口,表示该设备是一个 VGA 控制器。 |
设备信息关键字段解释
| 字段 | 含义 |
|---|---|
10de | NVIDIA 的供应商ID(Vendor ID),用于标识硬件供应商。 |
2584 | 设备 ID (Device ID),标识具体的硬件型号(例如 RTX 3060 的设备 ID 是 2584)。 |
(rev a1) | 硬件修订版本号,表示该设备的硬件版本(a1 是十六进制值)。 |
[0300] | 类别代码,表示该设备属于 VGA 兼容控制器类别。 |
[1458:4134] | 子系统 Vendor ID 和 Device ID,标识显卡的具体型号和厂商。 1458是Gigabyte(技嘉)的供应商ID,4134是主板型号ID |
使用GPU监控工具
安装intel-gpu-tools
1 | sudo apt install intel-gpu-tools |
查看GPU信息
1 | lsgpu |
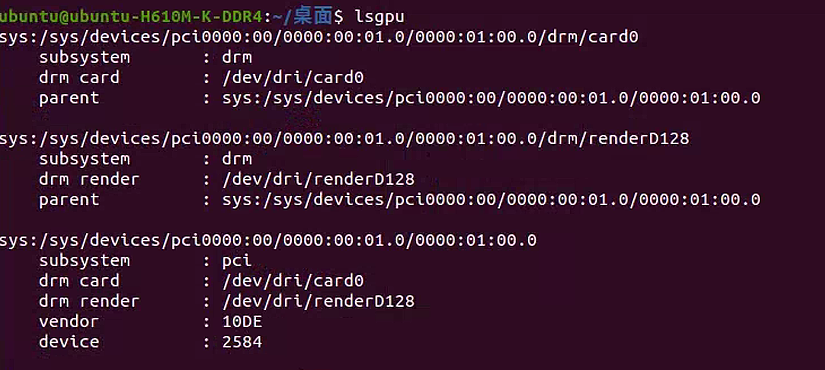
- 第一部分 (
sys:/sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0/drm/card0):
- 这是显卡的系统设备路径
subsystem : drm表示这是一个 DRM (Direct Rendering Manager) 子系统drm card : /dev/dri/card0是显卡的设备文件路径,用于系统访问显卡parent指向父设备的路径,即 PCI 设备路径
- 第二部分 (
sys:/sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0/drm/renderD128):
这是显卡渲染设备的路径
subsystem : drm同样表示这是 DRM 子系统drm render : /dev/dri/renderD128是渲染设备的文件路径,用于 GPU 渲染操作它与第一个设备共享相同的父设备
第三部分显示了系统中 GPU 设备的基本信息。让我来解析一下这些信息:
您的系统有一张 NVIDIA 显卡:
供应商 ID (vendor): 10DE(这是 NVIDIA 的供应商代码)
设备 ID (device): 2584
显卡的设备路径:
显卡路径:/dev/dri/card0
渲染设备路径:/dev/dri/renderD128
PCI 总线路径:0000:01:00.0
其中
card0主要负责显示输出,而renderD128主要负责 GPU 渲染计算。
使用权威网站查询 PCI/PCIe 设备 ID信息
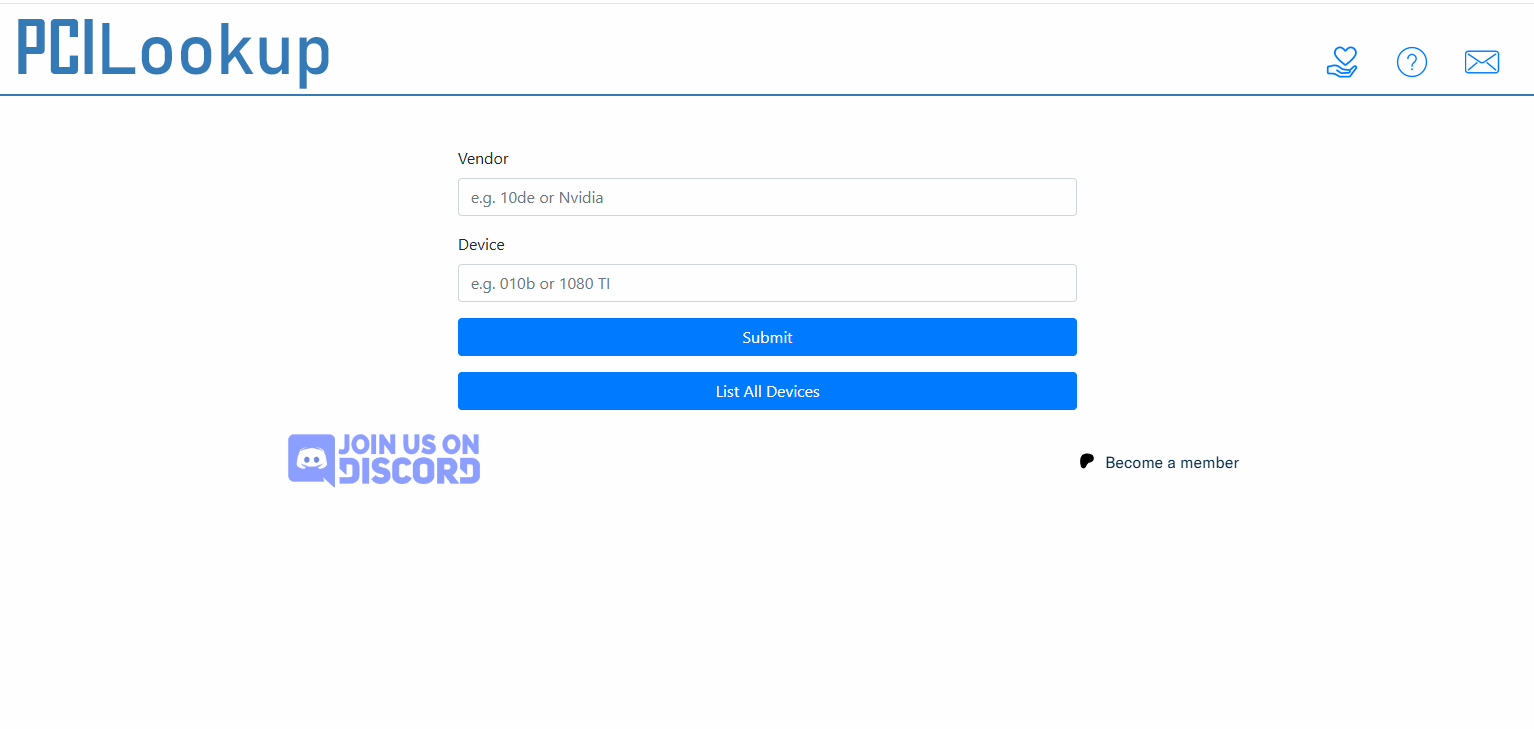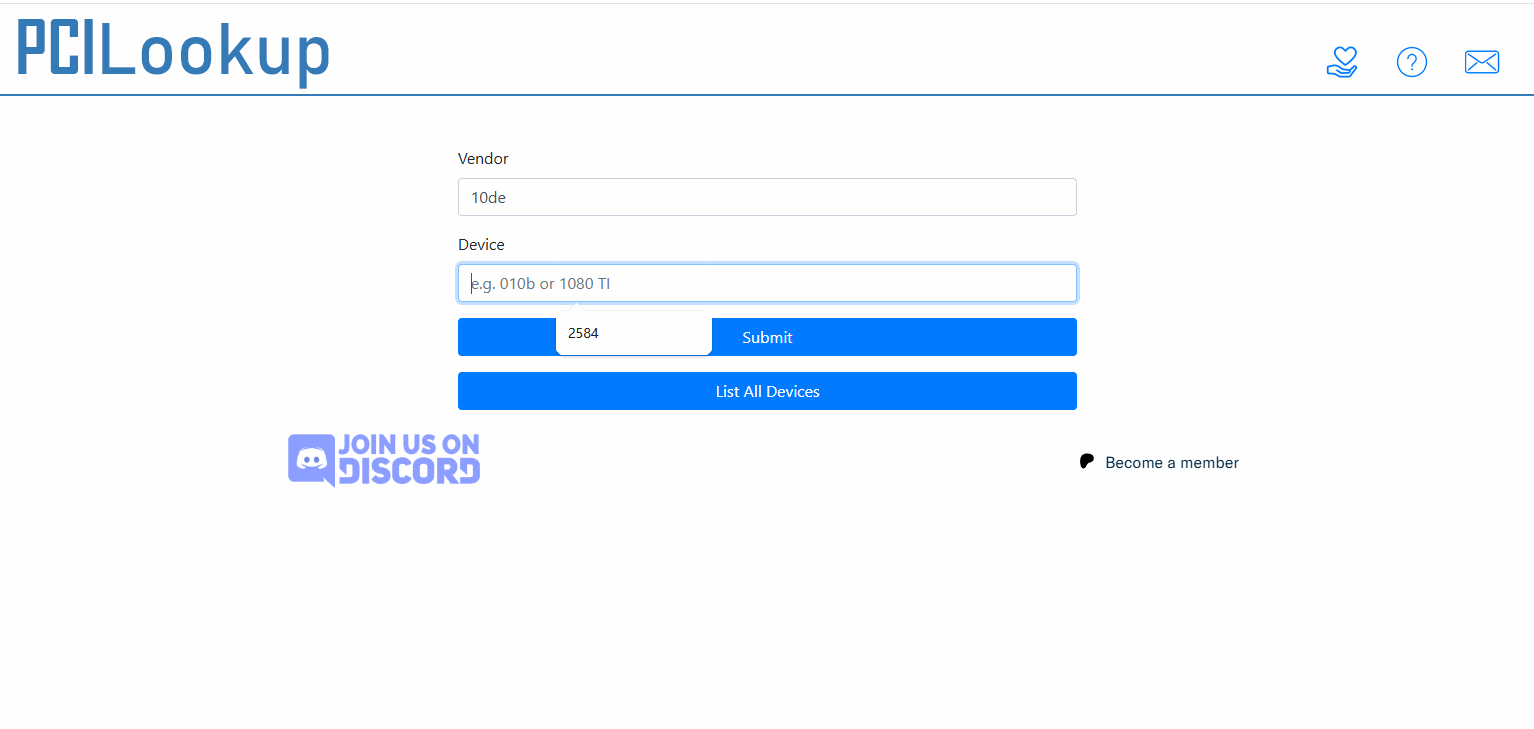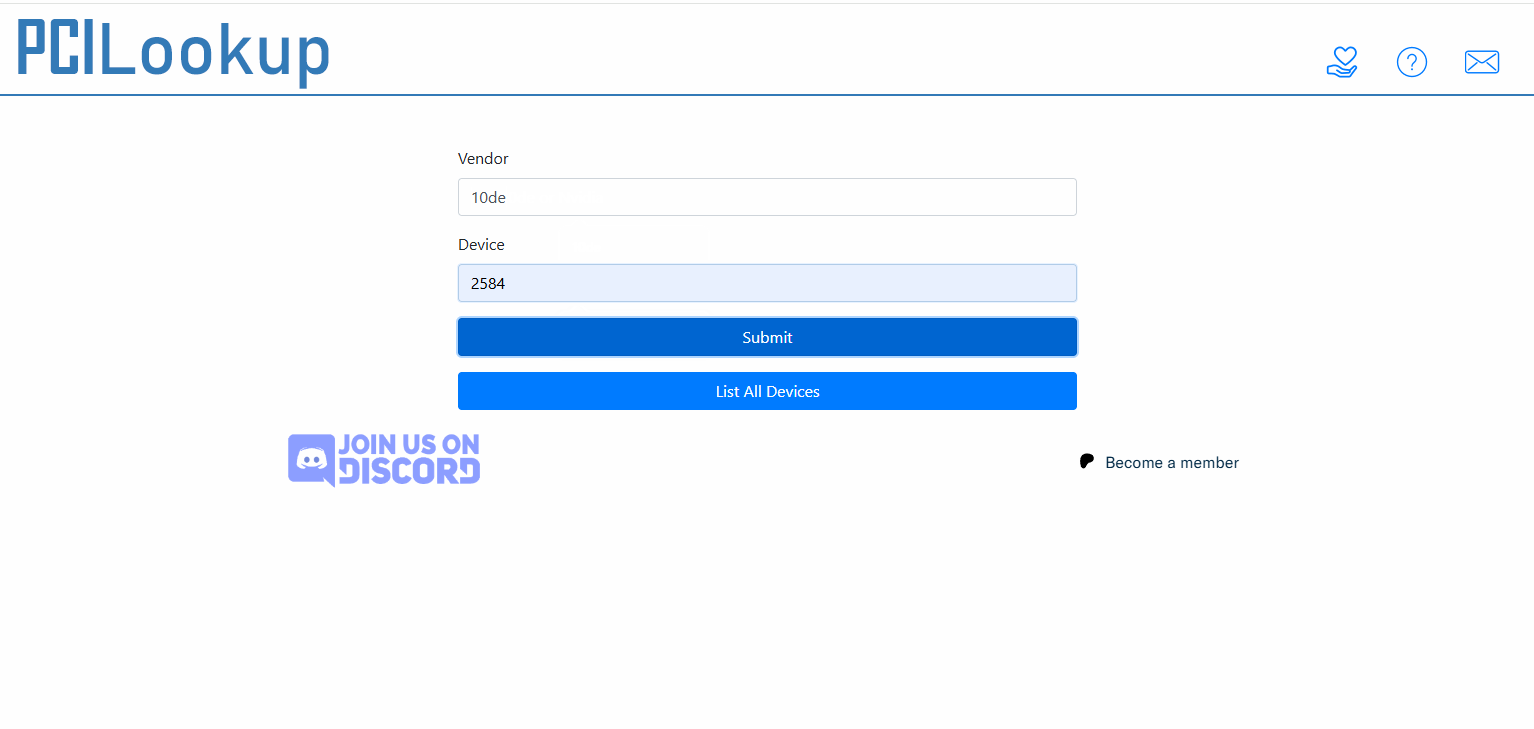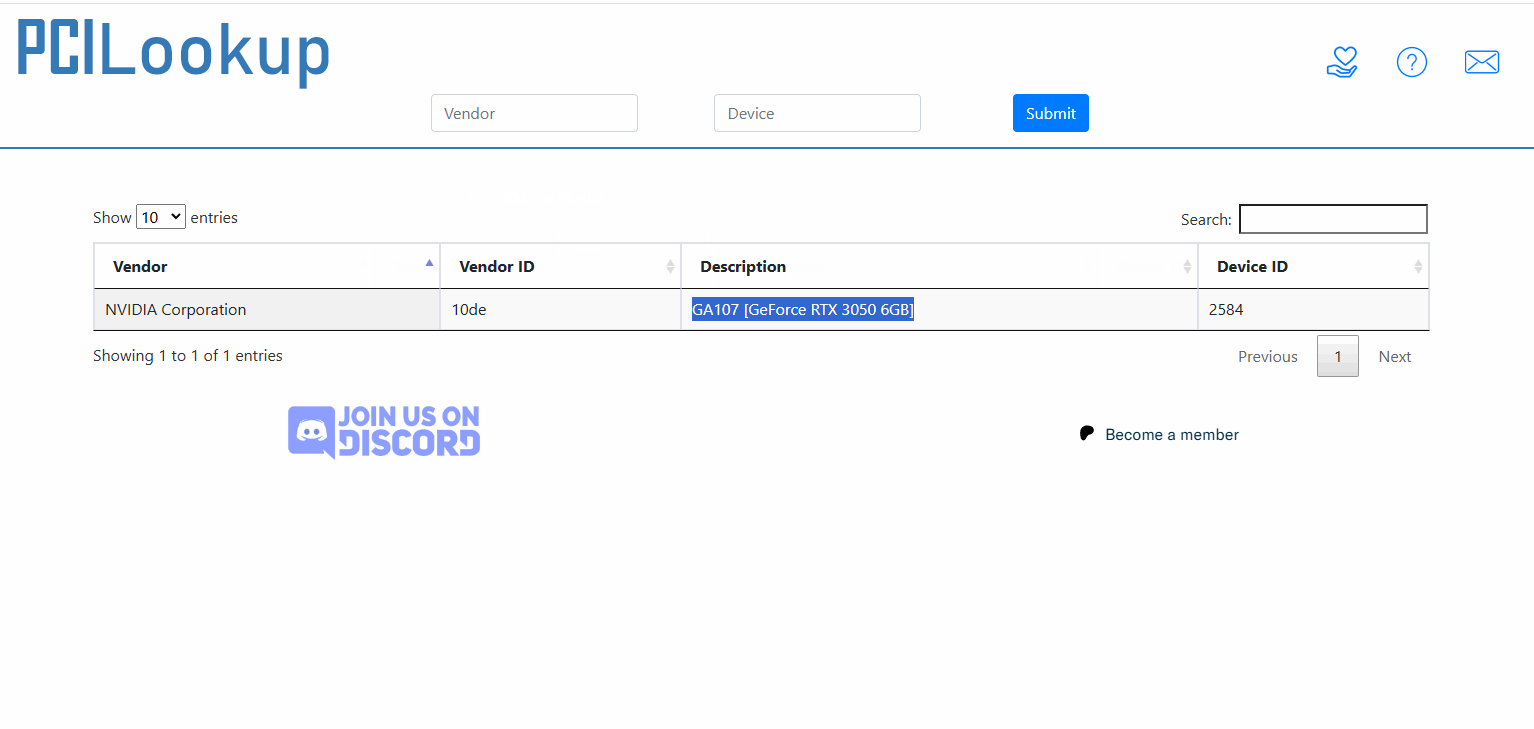
可以通过以下权威网站查询具体的显卡型号:
输入刚刚获得的信息:
- Vendor ID: 10de (NVIDIA Corporation)
- Device ID: 2584 (十六进制为 0x2584)
这是最常用的 PCI ID 查询网站
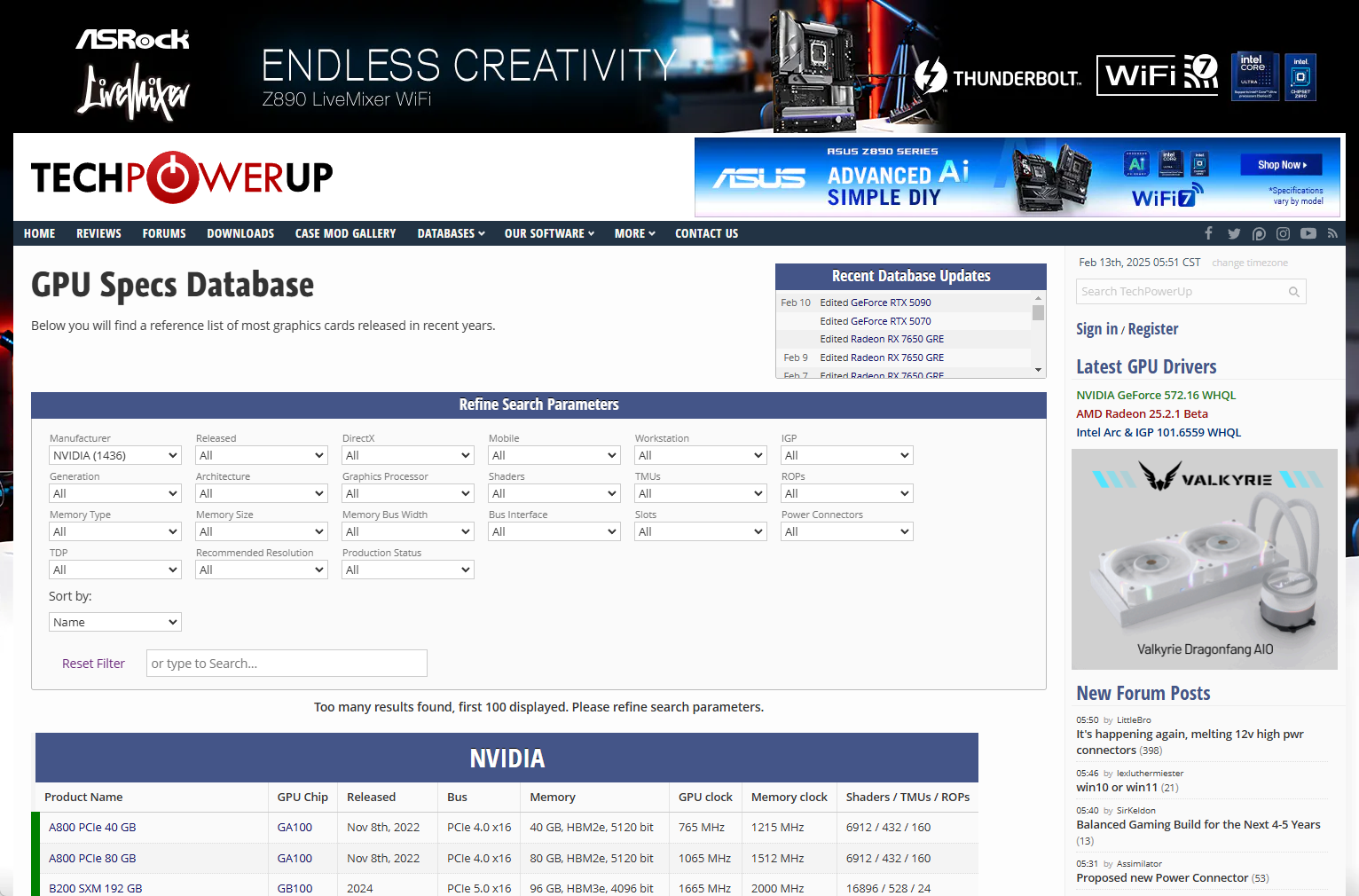
这些数据库会定期更新以包含新发布的硬件设备信息。由于有些新设备可能还未被收录,建议查询多个来源进行交叉验证。
使用CPU-X(Linux版CPU-Z)
精通技术的 Windows 很多用户可能使用 CPU-Z。它是一个极好的实用程序,用于收集 Windows 中应用程序无法获得的全面系统信息。但是 CPU-Z 在 Linux 上不可用。不要灰心!GitHub 上一个名为 X0rg 的开发人员创建了一个 CPU-Z 克隆,名为CPU-X for Linux。
CPU-X可以提供包括处理器、主板、内存、系统、显卡、性能等完整的硬件信息。
安装CPU-X
1 | sudo apt install cpu-x |
安装成功后
双击输入密码启动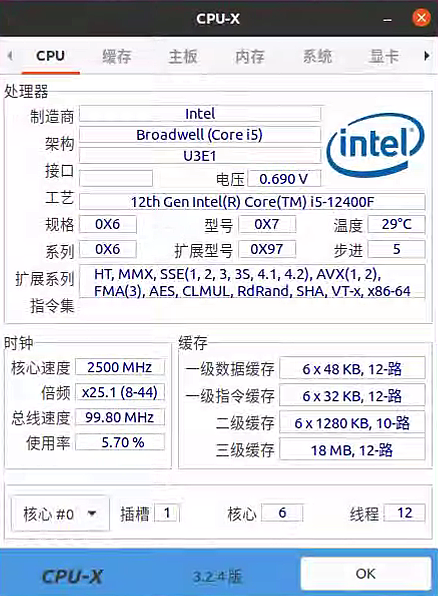

也可以通过命令行控制启动(支持多种方式显示)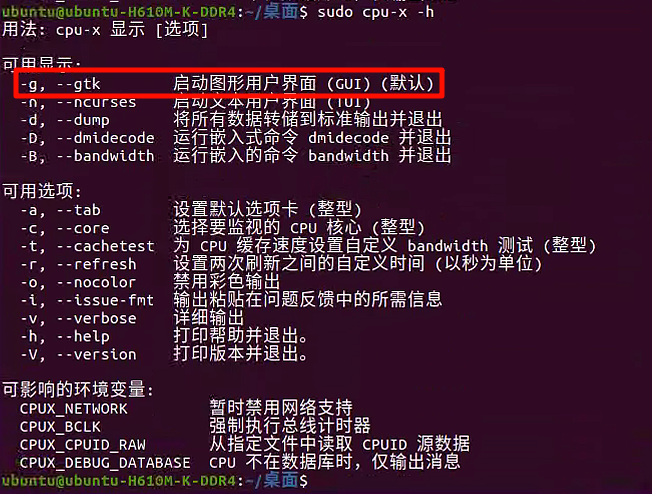
更多显卡信息获取方式
为了获取更详细或针对特定品牌显卡的实时信息,可以使用以下专用命令:
NVIDIA GPU:
1
nvidia-smi
(这是最常用、信息最全面的NVIDIA GPU监控工具)
AMD GPU:
1
rocm-smi
(适用于安装了ROCm驱动的AMD显卡)
所有 PCI 设备(包括显卡):
1
2
3
4
5lspci
lspci | grep -i vga
lspci -v | grep -A 10 VGA
lspci | grep -i nvidia
lspci -vnn | grep VGA -A 12(这些命令在前面已有详细解释,用于从不同维度查询PCI设备信息)
关于Nouveau驱动
在您使用 lspci -v 等命令的输出中,可能会看到 Kernel driver in use: nouveau。那么,Nouveau是什么呢?
Nouveau 是一个开源的NVIDIA显卡驱动程序,专门为Linux系统开发。这个名字来自法语,意思是“新的”。
Nouveau驱动的特点:
- 完全开源,由社区维护。
- 默认包含在大多数Linux发行版中,提供基本的显示功能。
- 相比NVIDIA官方闭源驱动:
- 功能较为基础。
- 性能相对较低,尤其是在3D渲染和游戏方面。
- 不支持部分高级特性,最关键的是不支持CUDA。
重要提示:如果您使用Linux系统进行深度学习、科学计算或任何需要GPU加速的任务,必须禁用Nouveau驱动并安装NVIDIA官方驱动。这是成功配置CUDA环境的前提。
安装NVIDIA驱动
确认显卡信息后,我们开始安装NVIDIA驱动。有两种主要的安装方法:
方法一:通过系统包管理器安装(推荐初学者)
从Ubuntu 18.04 LTS开始,用户可以通过”软件和更新 - 附加驱动”工具安装NVIDIA驱动程序。这一功能在后续的 LTS 版本(如 20.04 、22.04 和 24.04)中得到了持续改进和支持。
步骤:
- 打开”Software & Updates”(软件和更新)应用程序
- 切换到”Additional Drivers”(附加驱动)选项卡
- 在列表中选择适合的NVIDIA驱动版本
- 点击”Apply Changes”(应用更改)以安装驱动
- 重启系统
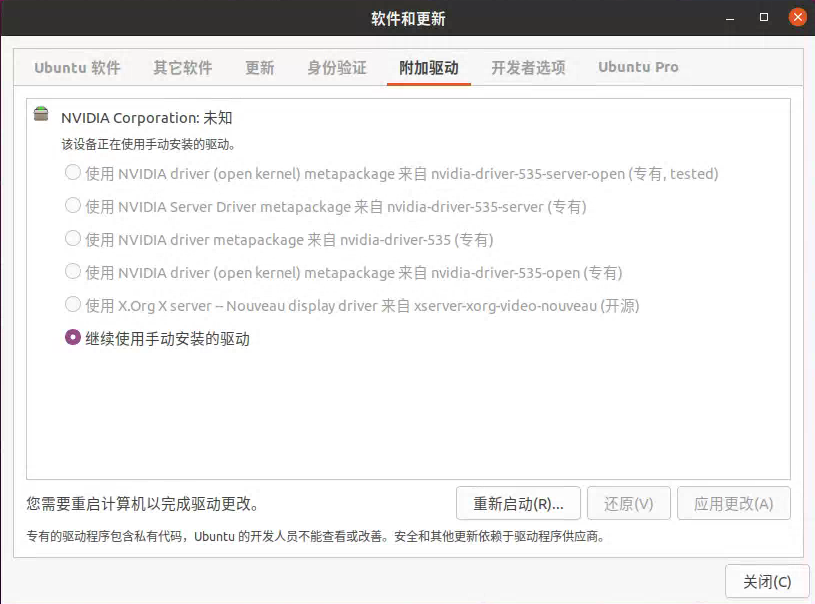
驱动选项说明:
默认选择第一个选项
安装即可
| 选项 | 类型 | 说明 |
|---|---|---|
| NVIDIA driver (open kernel) metapackage 来自 nvidia-driver-535-server-open | 专有测试版 | 使用开放内核的NVIDIA服务器驱动元包,经过测试 |
| NVIDIA Server Driver metapackage 来自 nvidia-driver-535-server | 专有 | NVIDIA服务器版本驱动程序元包 |
| NVIDIA driver metapackage 来自 nvidia-driver-535 | 专有 | 标准NVIDIA驱动程序元包 |
| NVIDIA driver (open kernel) metapackage 来自 nvidia-driver-535-open | 专有 | 使用开放内核的标准NVIDIA驱动元包 |
| X.Org X server – Nouveau display driver 来自 xserver-xorg-video-nouveau | 开源 | 开源的Nouveau显示驱动程序 |
| 继续使用手动安装的驱动 | - | 保持当前手动安装的驱动程序不变 |
方法二:手动安装(推荐生产环境)
0. 卸载旧驱动(如有)+ 禁用开源驱动 nouveau
卸载旧驱动
1 | sudo apt-get purge '^nvidia-.*' |
禁用开源驱动 Nouveau: Nouveau是Linux内核自带的开源NVIDIA驱动,与官方闭源驱动冲突,需要禁用。
1 | # sudo bash -c "echo 'blacklist nouveau' >> /etc/modprobe.d/blacklist-nouveau.conf" |
重启后,通过 lsmod | grep nouveau 确认Nouveau已被禁用(应无任何输出)
1. 下载官方驱动
访问NVIDIA驱动下载官网,根据你的显卡型号和操作系统选择并下载最新的驱动安装包(一个 .run 文件)
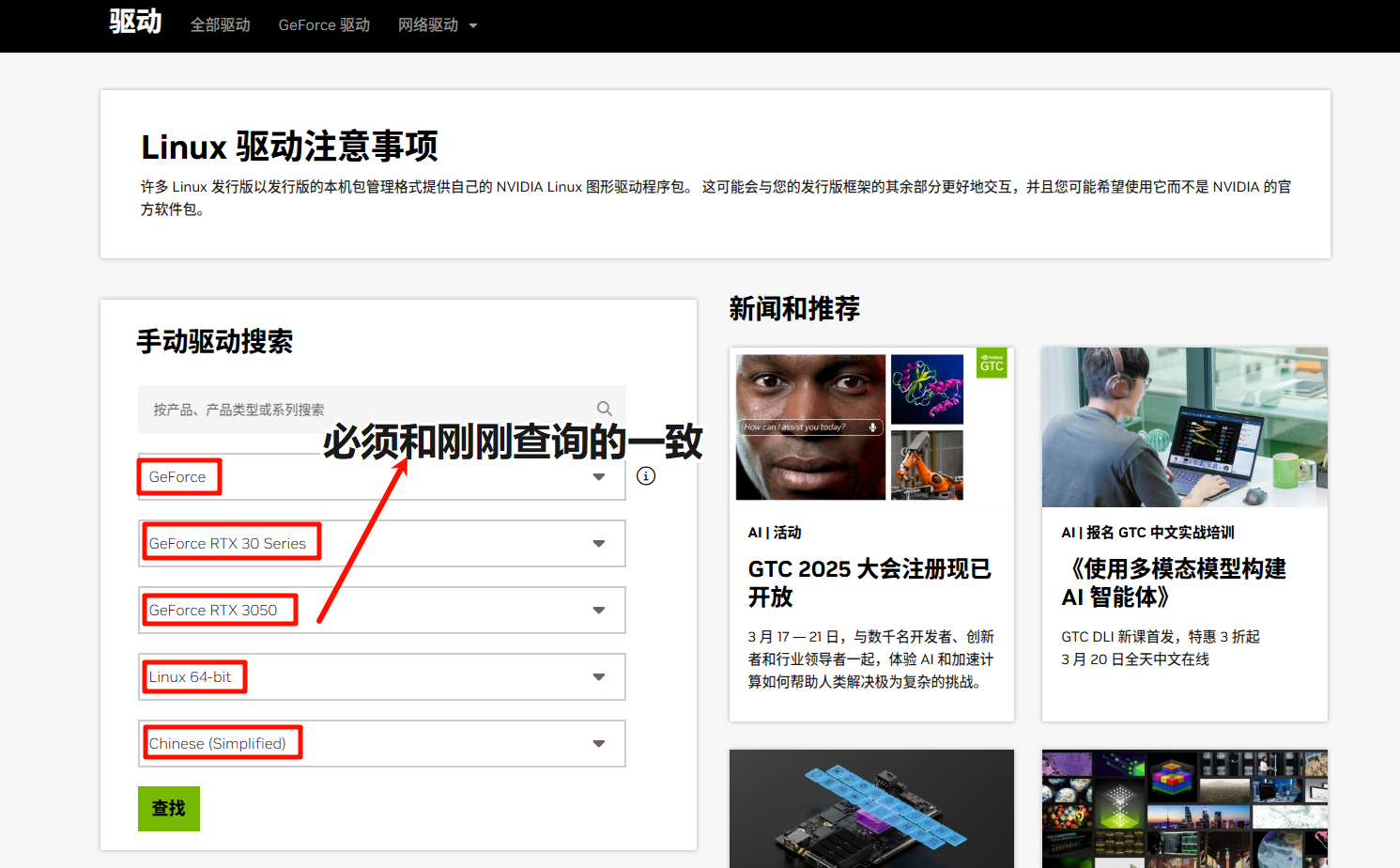
点击查找后,跳转到驱动主页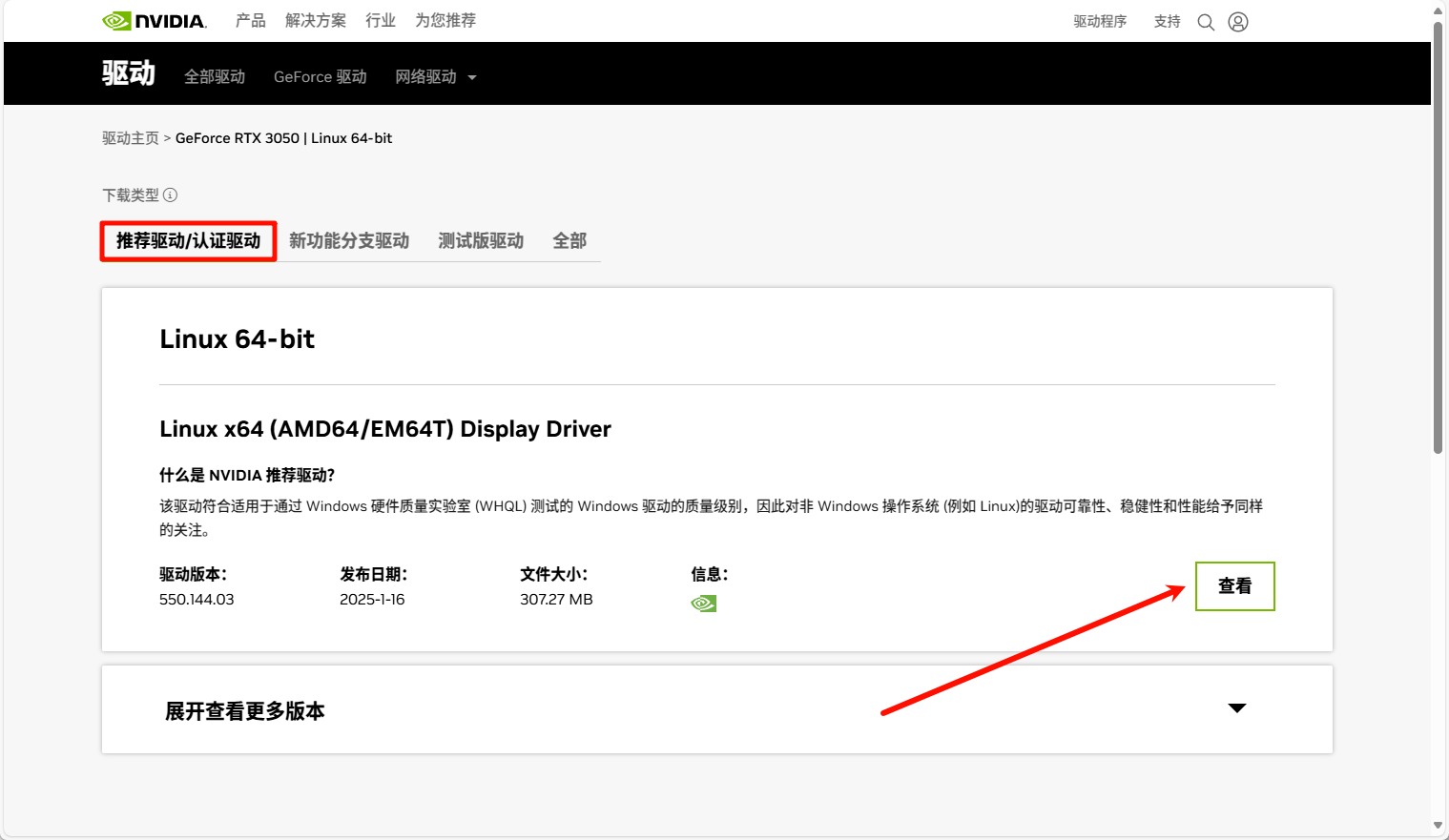
下载最新版推荐驱动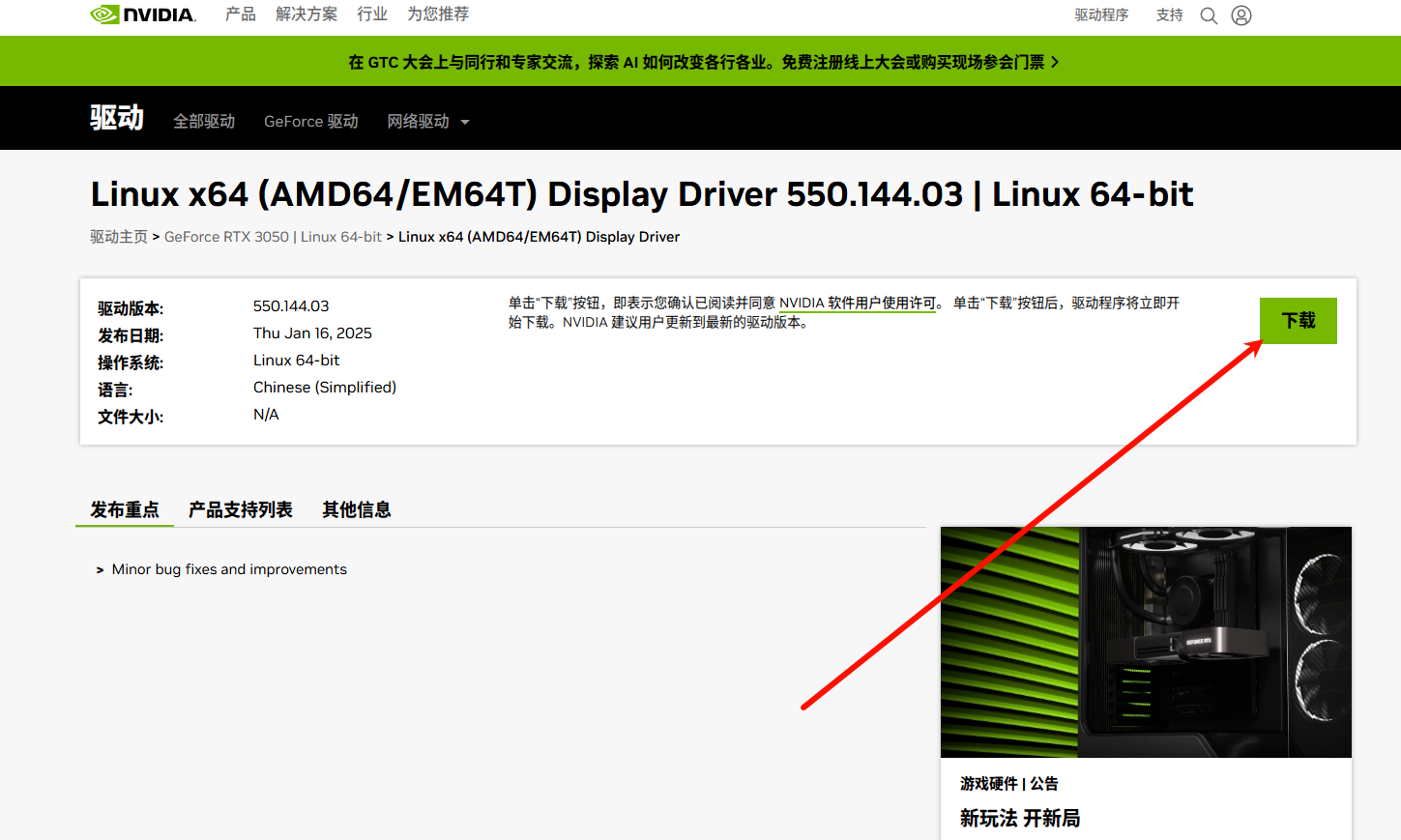
也可使用wget命令下载
1 | wget https://us.download.nvidia.com/XFree86/Linux-x86_64/550.144.03/NVIDIA-Linux-x86_64-550.144.03.run |

2. 安装编译依赖
1 | sudo apt update |
编译工具作用说明:
| 命令 | 功能 | 作用范围 |
|---|---|---|
gcc | 安装gcc编译器,用于编译C代码 | Nvidia驱动的某些模块可能需要C语言支持 |
g++ | 安装g++编译器,用于编译C++代码 | Nvidia驱动的某些部分可能需要C++支持 |
make | 安装make工具,用于自动化构建 | 简化软件的编译过程,执行驱动程序的安装脚本,确保正确安装Nvidia驱动 |
initramfs-tools | 安装initramfs-tools工具集,用于管理初始化内存文件系统(initramfs) | 管理系统启动时加载的驱动程序和模块,确保Nvidia驱动在系统启动时加载 |

3. 运行安装程序
进入.run文件所在的目录,赋予其执行权限并运行
1 | chmod +x NVIDIA-Linux-x86_64-550.144.03.run # 修改权限 |

1 | sudo ./NVIDIA-Linux-x86_64-550.144.03.run # 安装驱动 |
- 安装可选参数
--no-x-check:无需X服务--no-nouveau-check:跳过nouveau检查--no-opengl-files:避免与系统OpenGL冲突
安装过程:
选择“Continue installation”,回车
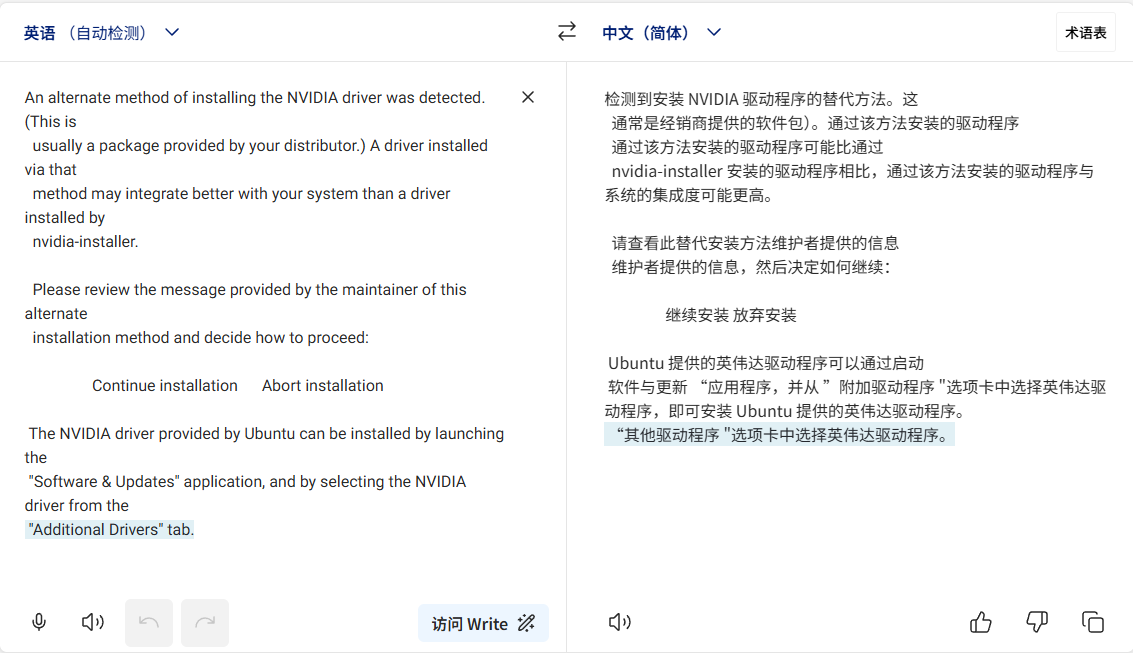
禁用nouveau驱动

NVIDIA 自动屏蔽 nouveau 驱动
下一步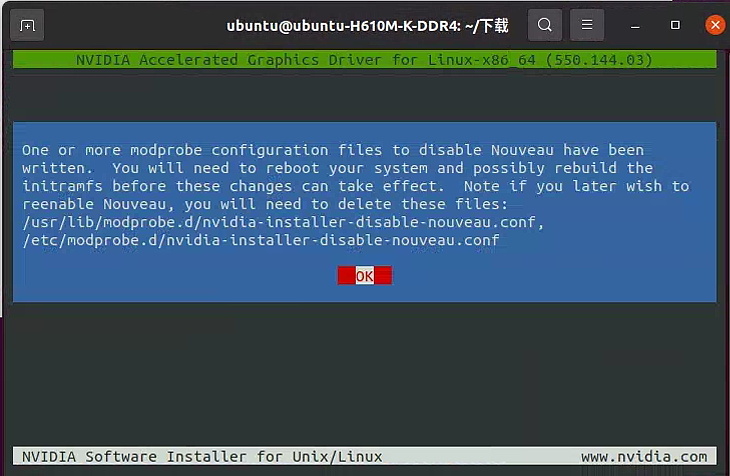
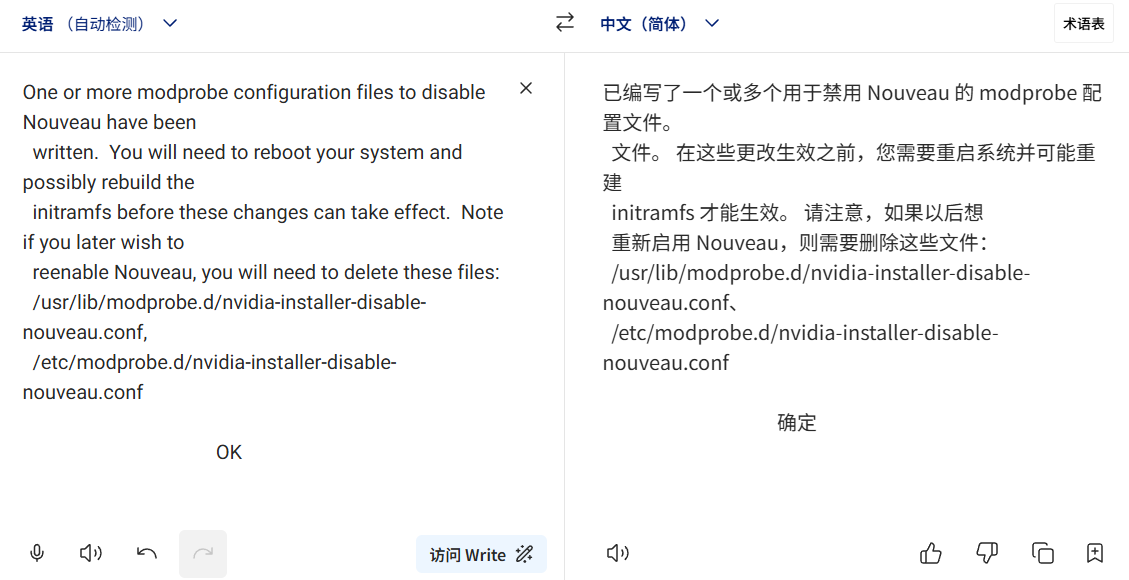
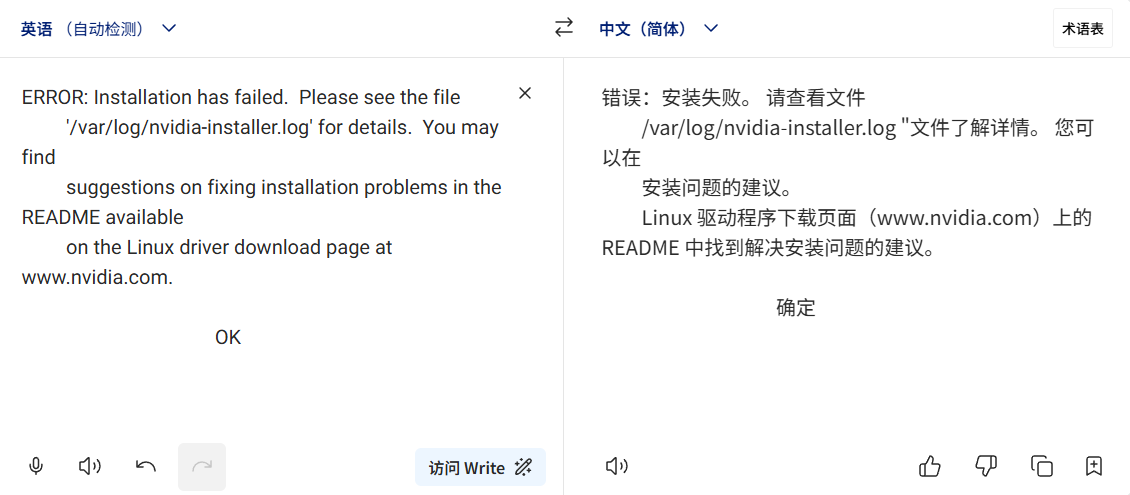
我这里选择终止安装(应该可以直接继续安装)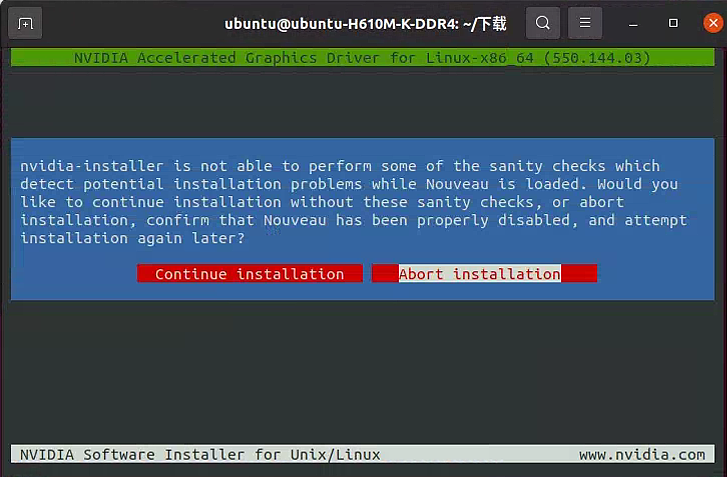
重新构建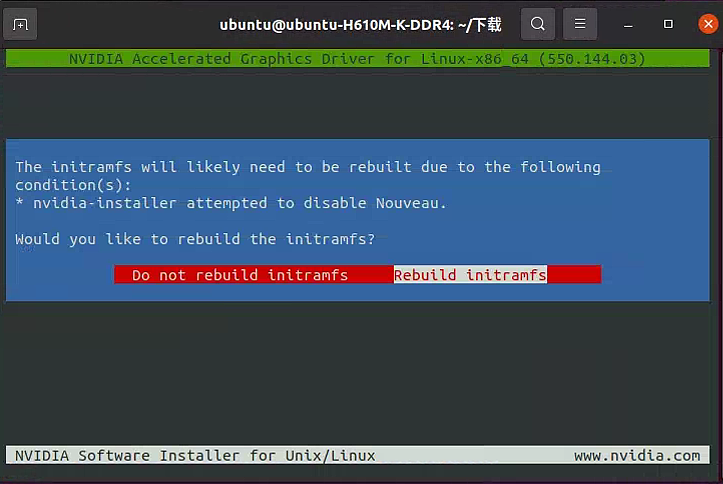

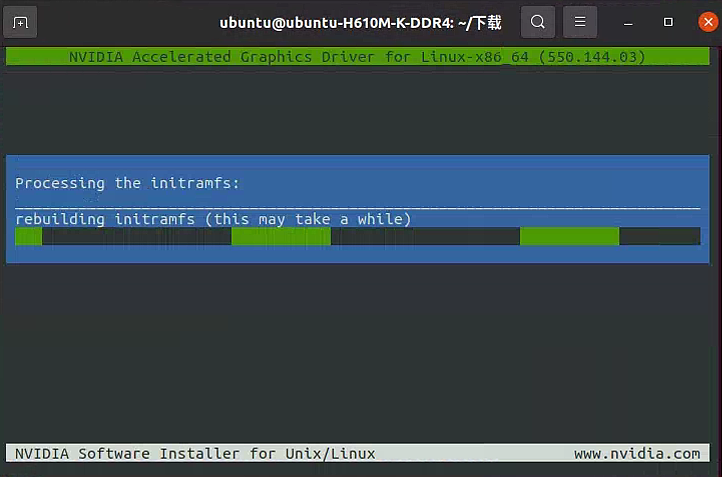
构建完成之后退出
重新执行安装命令,这次选择继续安装
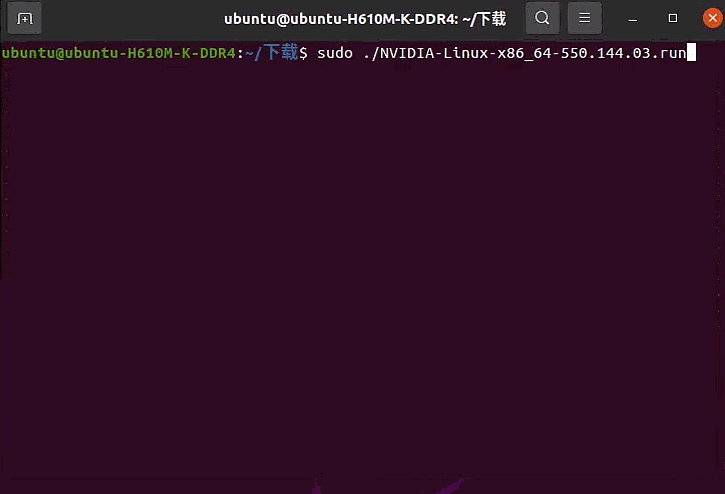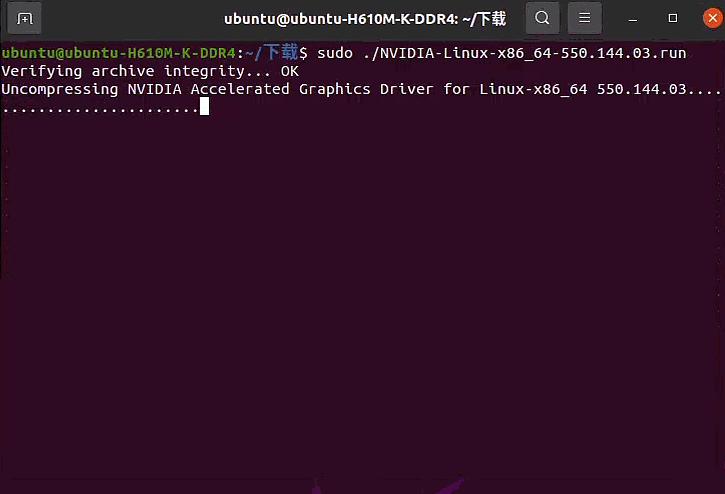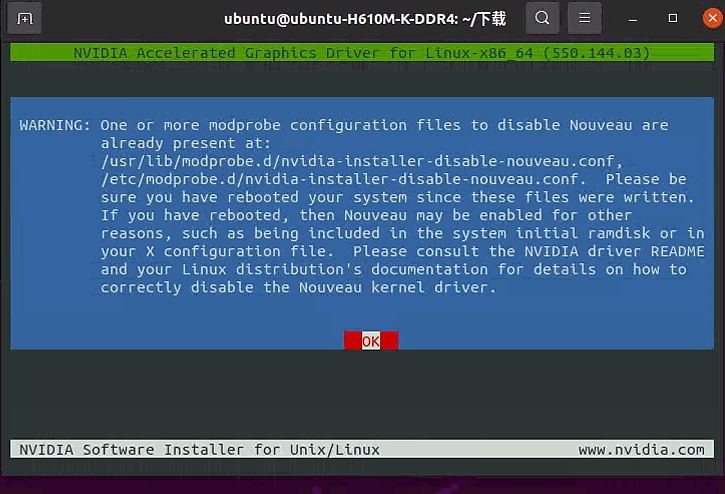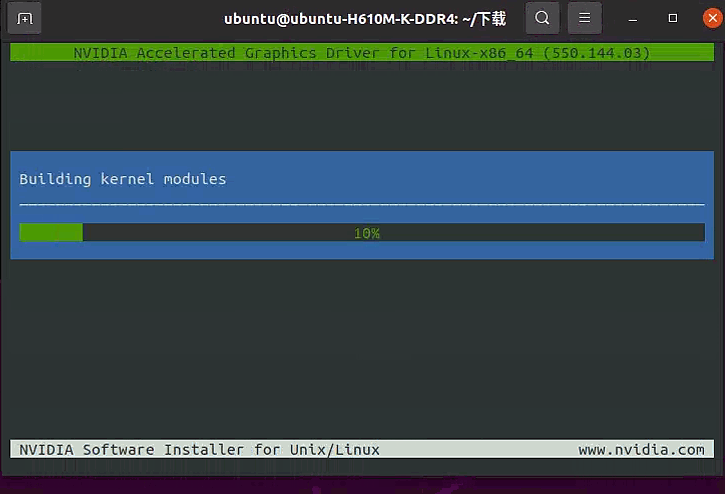
编译通过后,接着运行到下面这里,选择“Yes”
点击确定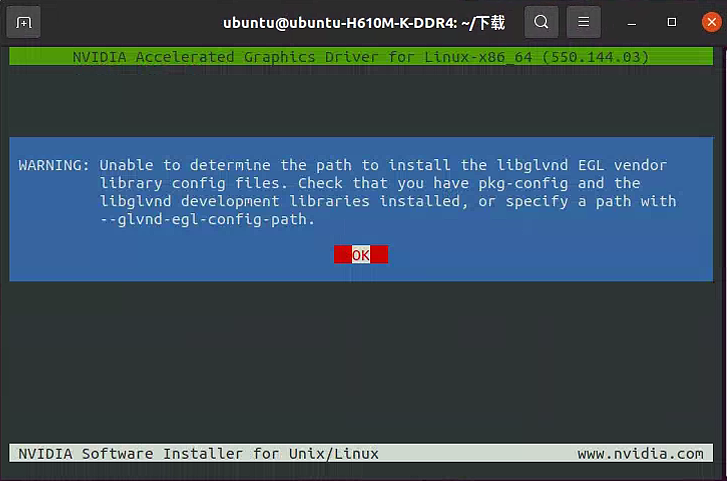
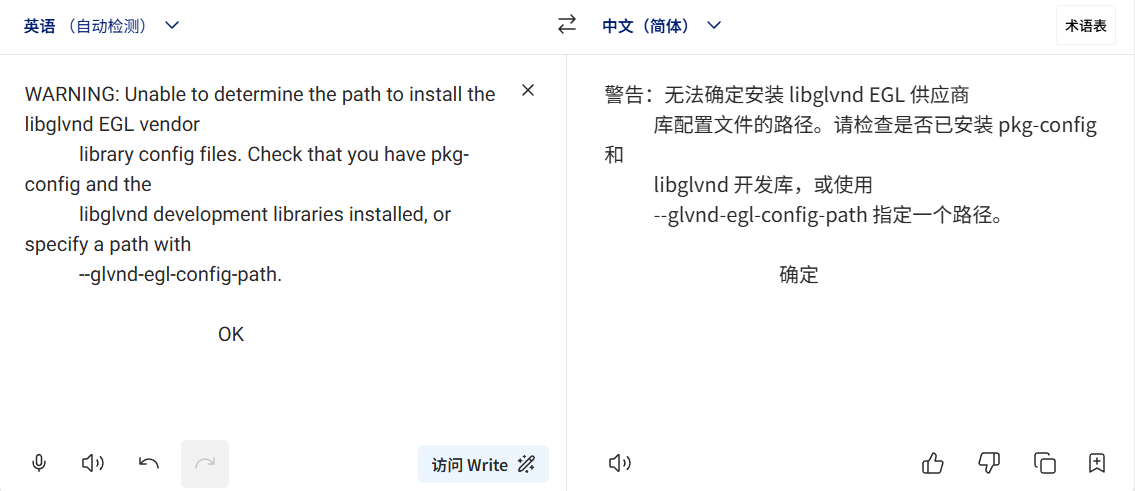
选择不需要重新构建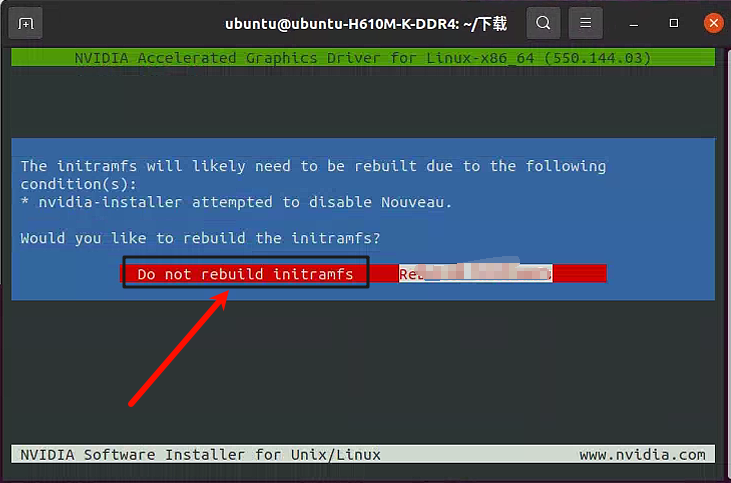

选择no
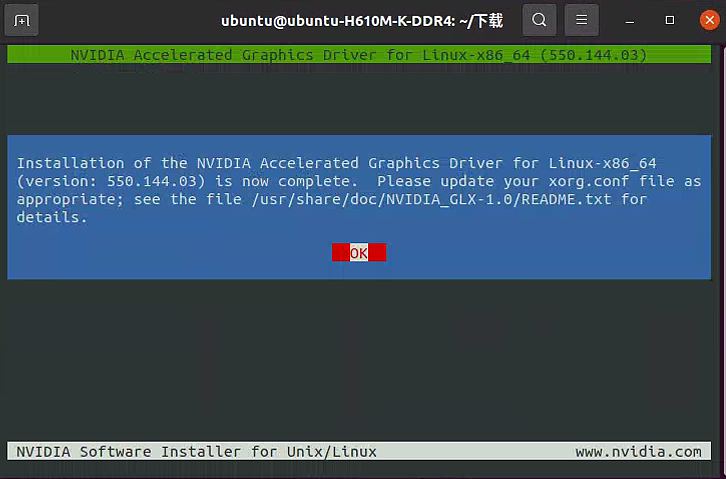
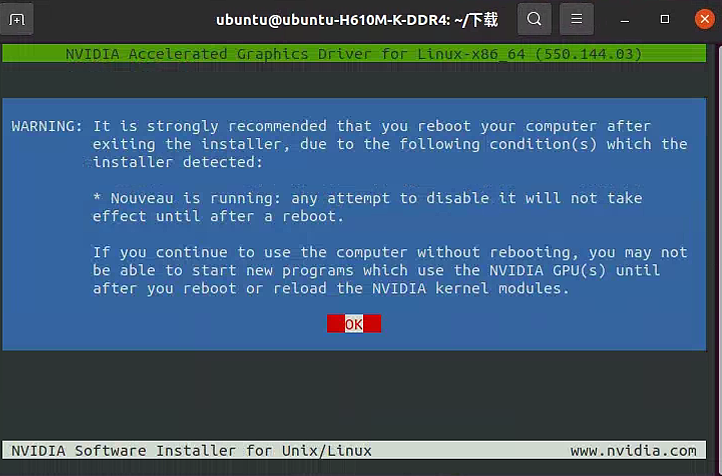
安装完成:
reboot重启电脑,终端运行nvidia-smi
1 | nvidia-smi |
nvidia-smi:这是 NVIDIA System Management Interface 的缩写,用于监控和管理 NVIDIA GPU 的状态。这个命令会显示 GPU 的型号、CUDA 版本等信息。如果一切正常,说明 NVIDIA 驱动和 CUDA 安装成功。
注意:右上角显示的不是当前安装的CUDA 版本,显示的是显卡最高支持的 CUDA 版本为 12.4
如果需要安装更高版本的CUDA,需要更新NVIDIA显卡驱动版本
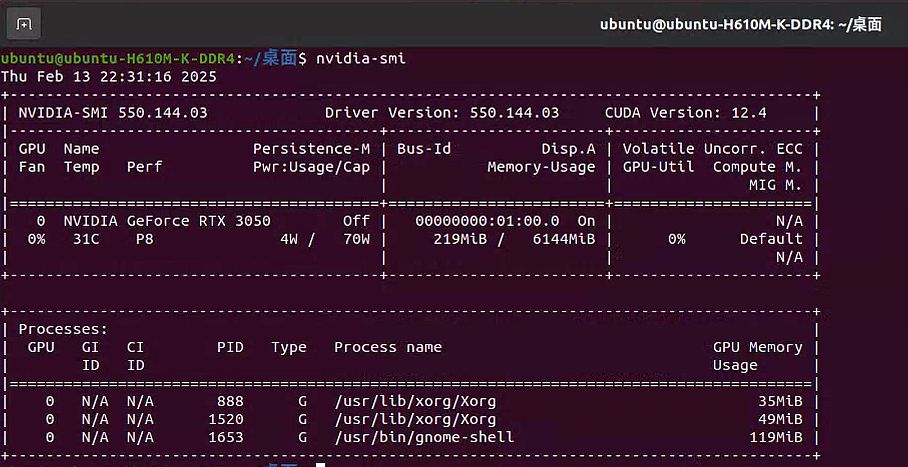 注意:右上角显示的不是当前安装的CUDA 版本,显示的是显卡最高支持的 CUDA 版本为 12.4
注意:右上角显示的不是当前安装的CUDA 版本,显示的是显卡最高支持的 CUDA 版本为 12.4实时监控GPU状态:
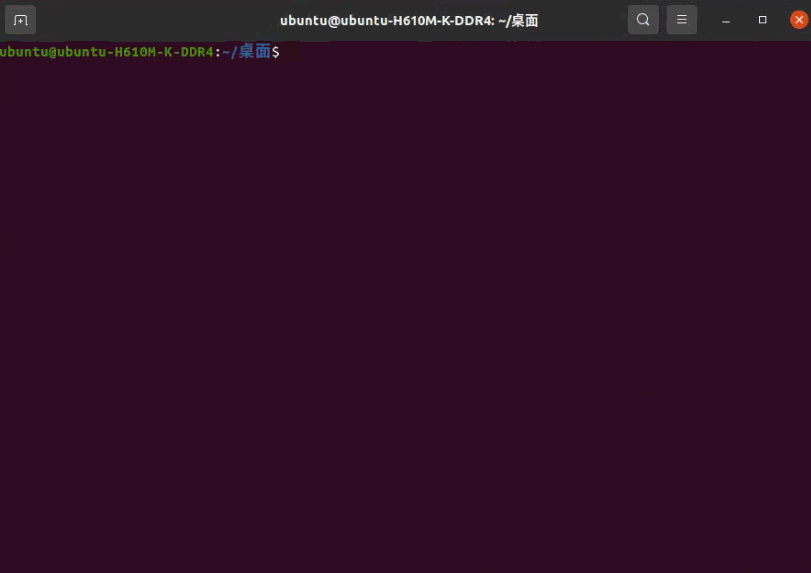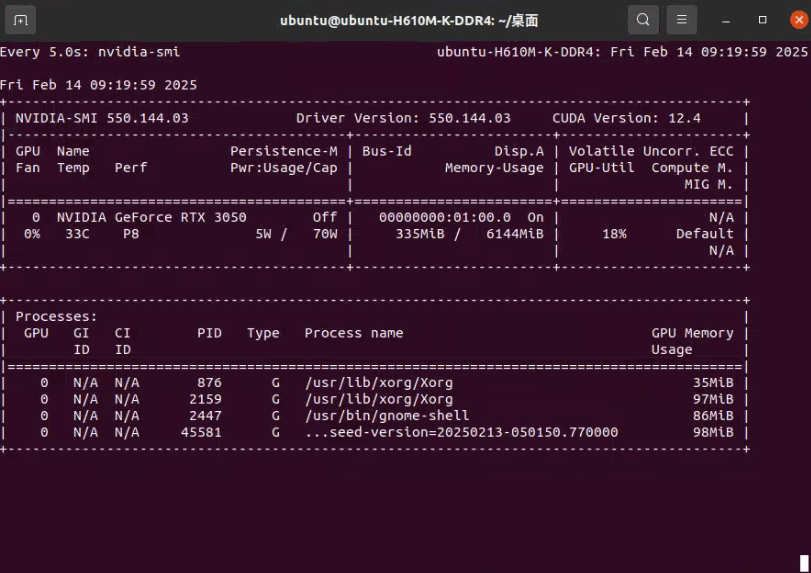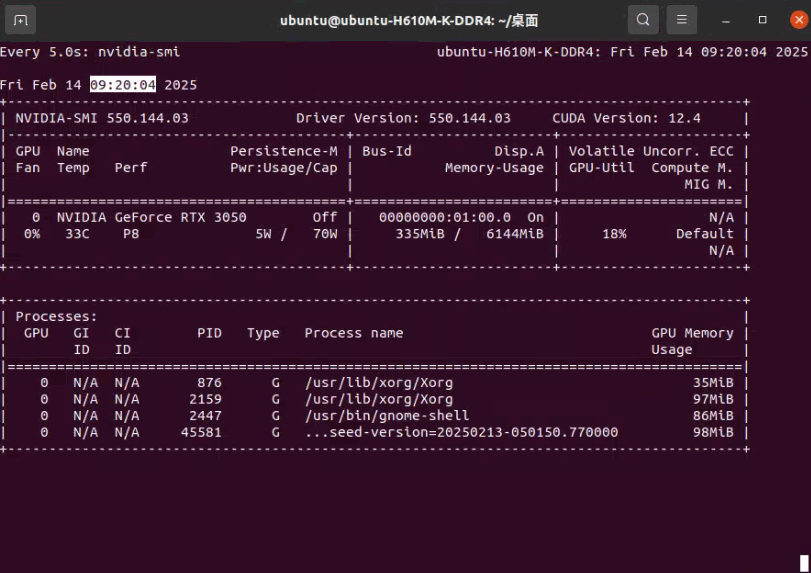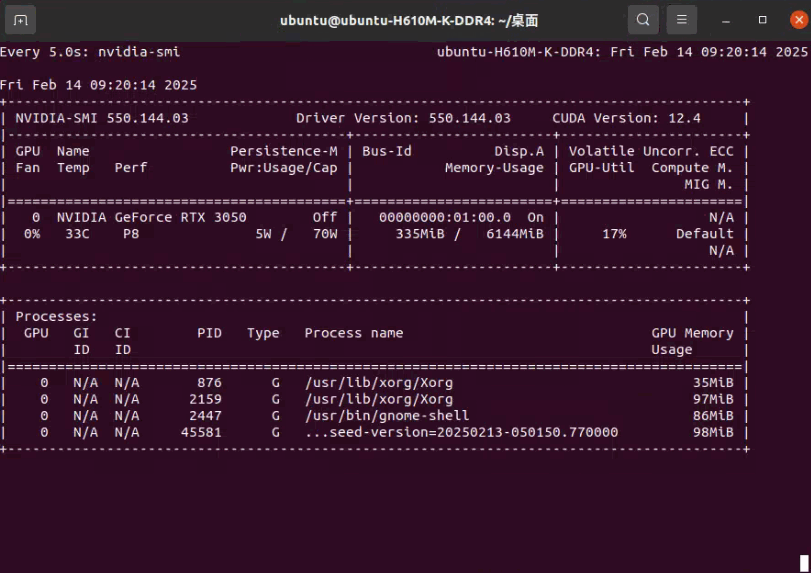
1 | # 每5秒刷新一次 |
直接在命令行中启动一个循环,每 5 秒刷新一次 GPU 状态,包括 GPU 的温度、使用率、内存使用情况、进程信息等,适用于简单的监控需求。
-l 5:这个选项指定了 -l(或 —loop)参数,表示每 5 秒刷新一次 GPU 的状态信息。
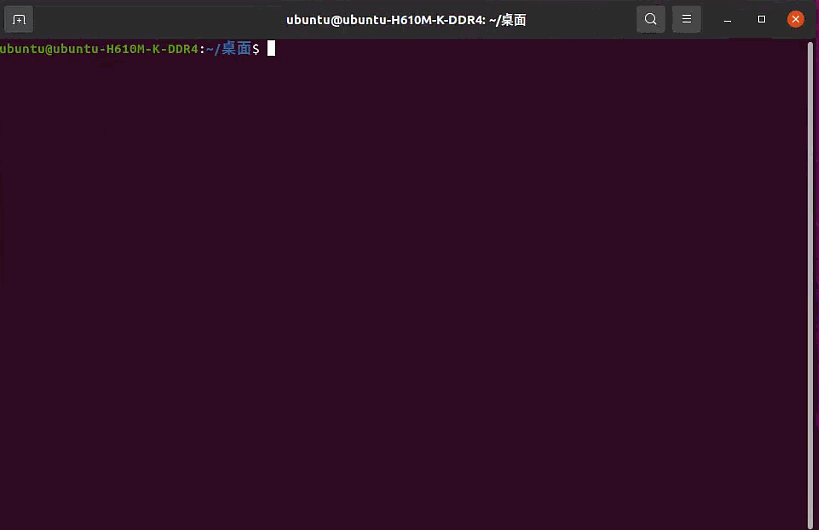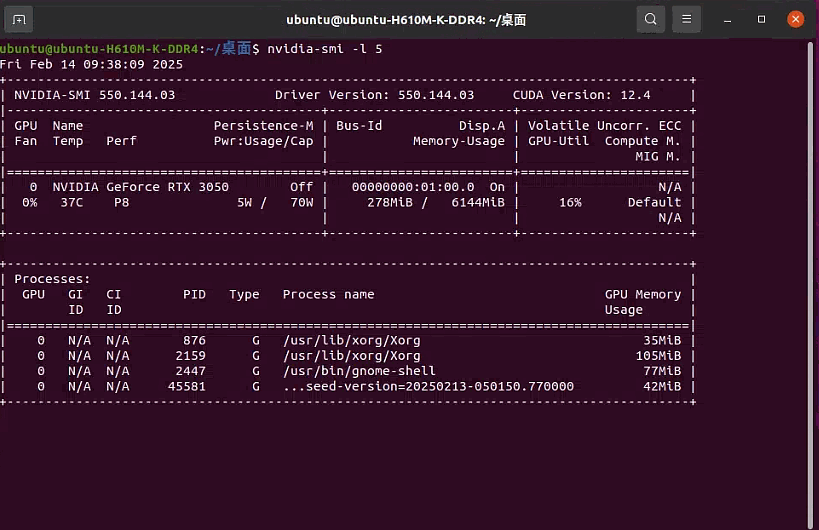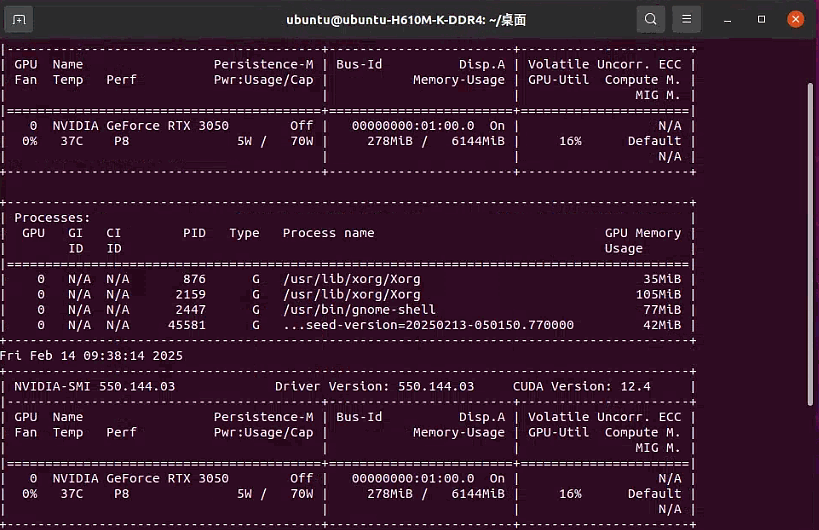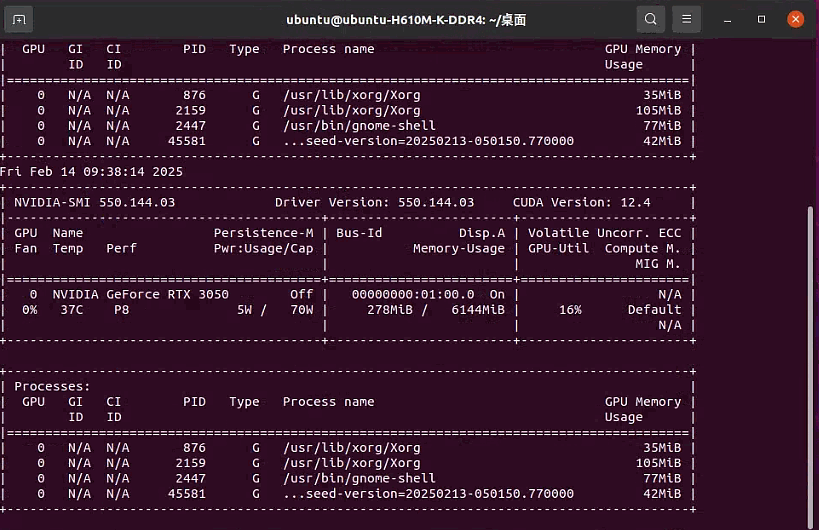
1 | # 使用watch命令 |
通过 watch 命令提供更丰富的交互性和持久性,每 5 秒执行一次 nvidia-smi,适合需要持续监控和更复杂交互的场景。
watch:这是一个在 Unix 和 Linux 系统中常用的命令,用于周期性地执行一个命令并显示其输出。相当于启动一个持续运行的进程,每 5 秒执行一次 nvidia-smi
-n 5:这个选项指定了每 5 秒执行一次 nvidia-smi 命令。
安装过程注意事项:
- 如果提示nouveau驱动冲突,选择自动禁用
- 在Secure Boot启用的系统中,需要对内核模块进行签名
常见问题与解决方案
| 问题 | 解决方法 |
|---|---|
nvidia-smi 报错 | 注册 NVIDIA 公钥到 MOK 列表,并重启系统完成注册。 |
modprobe nvidia 报错 | 确保完成 MOK 注册,或禁用 Secure Boot。 |
| 无法进入 GRUB 菜单 | 快速按 Shift 或 Esc 键,或修改 GRUB 配置文件以显示菜单。 |
| MOK 管理界面未出现 | 检查 Secure Boot 是否启用,或手动触发 MOK 注册。 |
| NVIDIA 驱动仍然无法加载 | 禁用 Nouveau 驱动,或重新安装最新版本的 NVIDIA 驱动。 |
✅手动禁用nouveau通用驱动【针对服务器版(无图形界面)Ubuntu】
删除原有显卡驱动(需要彻底删除,否则安装时会报错)
1 | sudo apt-get remove --purge nvidia* |
修改blacklist.conf配置文件
1 | sudo vim /etc/modprobe.d/blacklist.conf |
在blacklist.conf文件末尾添加以下内容
1 | blacklist nouveau |
更新配置并重启
1 | sudo update-initramfs -u |
重启后输入下方命令,无输出则说明禁用成功
1 | lsmod | grep nouveau |
❌ nvidia-smi` 报错,提示无法与 NVIDIA 驱动通信
原因:
- Secure Boot 限制
- 当 Secure Boot 启用时,Linux 内核只会加载经过受信任密钥签名的模块。
- 如果 NVIDIA 驱动的公钥未被添加到系统的受信任密钥数据库中,内核将拒绝加载 NVIDIA 内核模块。
- 公钥未注册
- 安装程序生成了一个 X.509 证书(包含公钥),但它尚未被注册到 MOK 列表中。
- 因此,即使驱动已安装,内核也无法验证其签名的有效性。
- Secure Boot 限制
解决方法:
检查
Secure Boot状态 :1
mokutil --sb-state
如果输出为 SecureBoot enabled,继续下一步。
步骤 1:检查公钥文件是否存在
确保公钥文件
/usr/share/nvidia/nvidia-modsign-crt-F26065BA.der存在:1
ls /usr/share/nvidia/nvidia-modsign-crt-F26065BA.der
如果文件不存在,请重新运行 NVIDIA 驱动安装程序,并确保选择对内核模块进行签名。
步骤 2:注册 NVIDIA 公钥到 MOK 列表
使用
mokutil工具导入公钥:1
sudo mokutil --import /usr/share/nvidia/nvidia-modsign-crt-F26065BA.der
- 系统会提示你设置一个密码(用于确认信任公钥)。请记住这个密码,稍后需要在 MOK 管理界面中输入。
检查是否成功导入:
1
sudo mokutil --list-new
- 输出应显示刚刚导入的公钥文件路径。
步骤 3:重启计算机
重启系统以进入 MOK 管理界面:
1
sudo reboot
在启动时,按
Shift或Esc键进入 GRUB 菜单,然后选择 “Enroll MOK”(注册 MOK)。Shift键 :适用于大多数基于BIOS的系统。Esc键 :适用于某些基于UEFI的系统。按照屏幕提示完成以下操作:
- 选择 “Continue” 或 “Yes” 确认注册。
- 输入之前设置的密码。
完成后,系统会提示你重启计算机。
步骤 4:验证驱动是否正常工作
重启后,检查 NVIDIA 驱动是否正常加载:
1
nvidia-smi
- 如果显示 GPU 信息,则说明驱动安装成功。
如果仍然失败,可以尝试手动重新加载 NVIDIA 内核模块:
1
sudo modprobe nvidia
- 如果没有报错,则说明模块加载成功。
补充知识点:
- 什么是
Secure Boot?Secure Boot是 UEFI 固件的一项安全功能,用于确保只有经过数字签名的软件(如操作系统内核、驱动程序等)才能在系统启动时加载。- 如果
Secure Boot启用,未签名或签名无效的内核模块将无法加载。
什么是私钥和公钥?
- 私钥 :用于对文件(如内核模块)进行签名的密钥。它必须保密,只有你拥有。
- 公钥 :与私钥配对的密钥,用于验证签名的有效性。公钥需要注册到系统的 MOK(Machine Owner Key)列表中,以便
Secure Boot信任你的签名。
错误分析
- NVIDIA 驱动需要安装一个内核模块(nvidia.ko),而系统启用了 Secure Boot 和模块签名验证。
- 安装程序提供了两个选项:
- Sign the kernel module :如果希望 NVIDIA 驱动正常工作,并且系统启用了 Secure Boot,则需要对 NVIDIA 内核模块进行签名
- Install without signing :如果选择不签名,NVIDIA 内核模块将无法加载,除非禁用 Secure Boot
启用 Secure Boot,对 NVIDIA 内核模块进行签名简要步骤:
- 安装程序会引导你生成一个密钥对(如果还没有的话)。
- 使用该密钥对 NVIDIA 内核模块进行签名。
- 将公钥注册到系统的 MOK(Machine Owner Key)列表中。
- 系统会在下次启动时提示你确认信任该密钥(通过 MOK 管理界面)。
- 在启动时进入 MOK 管理界面(通常按 Shift 或 Esc 键进入 GRUB 菜单)。
- 选择 “Enroll MOK” 并输入之前设置的密码,确认信任公钥。
- 重启后,NVIDIA 驱动应该能够正常加载。
- 注意事项:
- 如果不熟悉密钥管理,需要一些额外的学习成本。
- 什么是
❌ modprobe nvidia 报错
原因:
- 可能是内核模块签名验证失败,或者 Nouveau 驱动仍在运行。
解决方法:
禁用 Nouveau 驱动:
1
2
3echo "blacklist nouveau" | sudo tee /etc/modprobe.d/blacklist-nouveau.conf
sudo update-initramfs -u
sudo reboot再次尝试加载 NVIDIA 模块:
1
sudo modprobe nvidia
❌ 无法进入 GRUB 菜单
原因:
- GRUB 菜单可能被隐藏或按键不正确。
解决方法:
快速按下以下按键:
Shift或Esc:尝试进入 GRUB 菜单。如果无效,修改 GRUB 配置文件以显示菜单:
1
sudo nano /etc/default/grub
修改以下行:
1
2GRUB_TIMEOUT_STYLE=menu
GRUB_TIMEOUT=5更新 GRUB:
1
sudo update-grub
重启系统,GRUB 菜单应该会自动显示。
❌ nvidia-smi 仍失败报错
原因:
- 可能是驱动版本不兼容或安装不完整。
解决方法:
卸载现有驱动:
1
sudo apt-get purge '^nvidia-.*'
重新安装最新版本的 NVIDIA 驱动:
1
2sudo apt update
sudo apt install nvidia-driver-<version>将
<version>替换为适合你 GPU 的驱动版本号。
安装CUDA Toolkit
CUDA是NVIDIA开发的并行计算平台,是使用GPU进行深度学习的基础。
方法一:通过包管理器【apt-get】安装
这种方法简单,但版本可能不是最新的。
1 | sudo apt-get install nvidia-cuda-toolkit |
方法二:手动安装(推荐)
1. 下载CUDA Toolkit
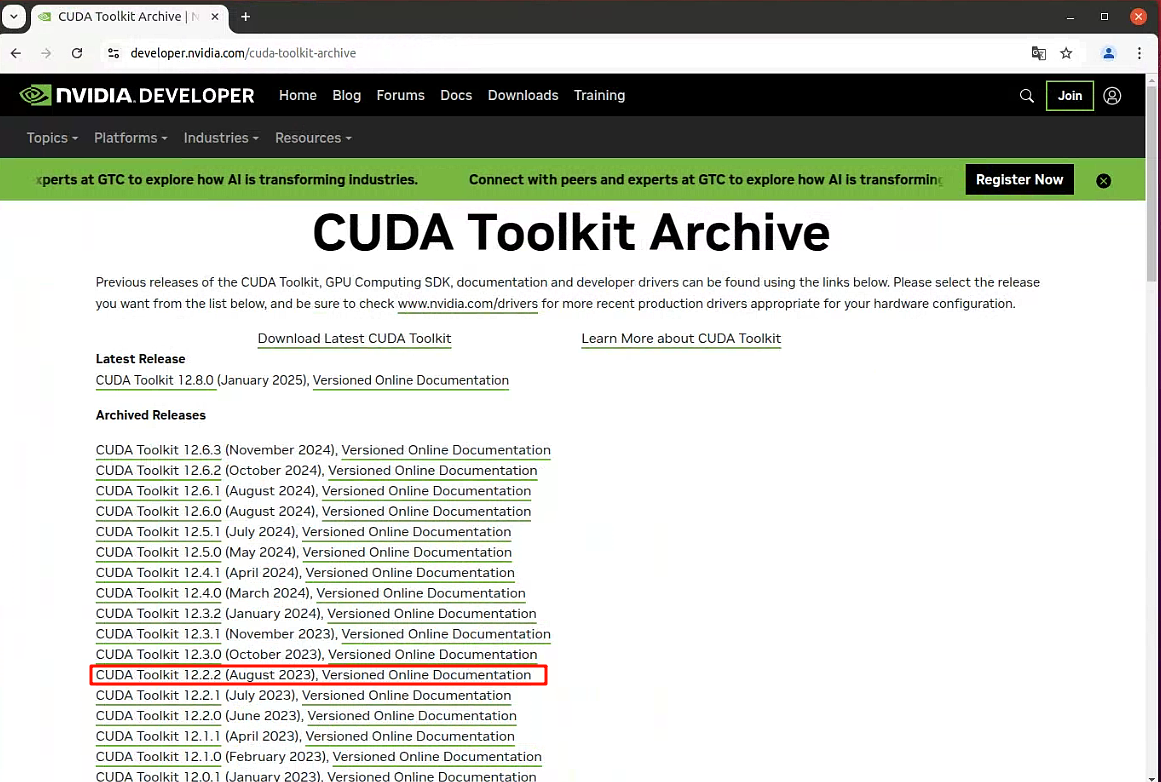
访问NVIDIA CUDA下载官网选择适合系统的CUDA版本,选择你的系统和安装方式。推荐使用 runfile(local)。
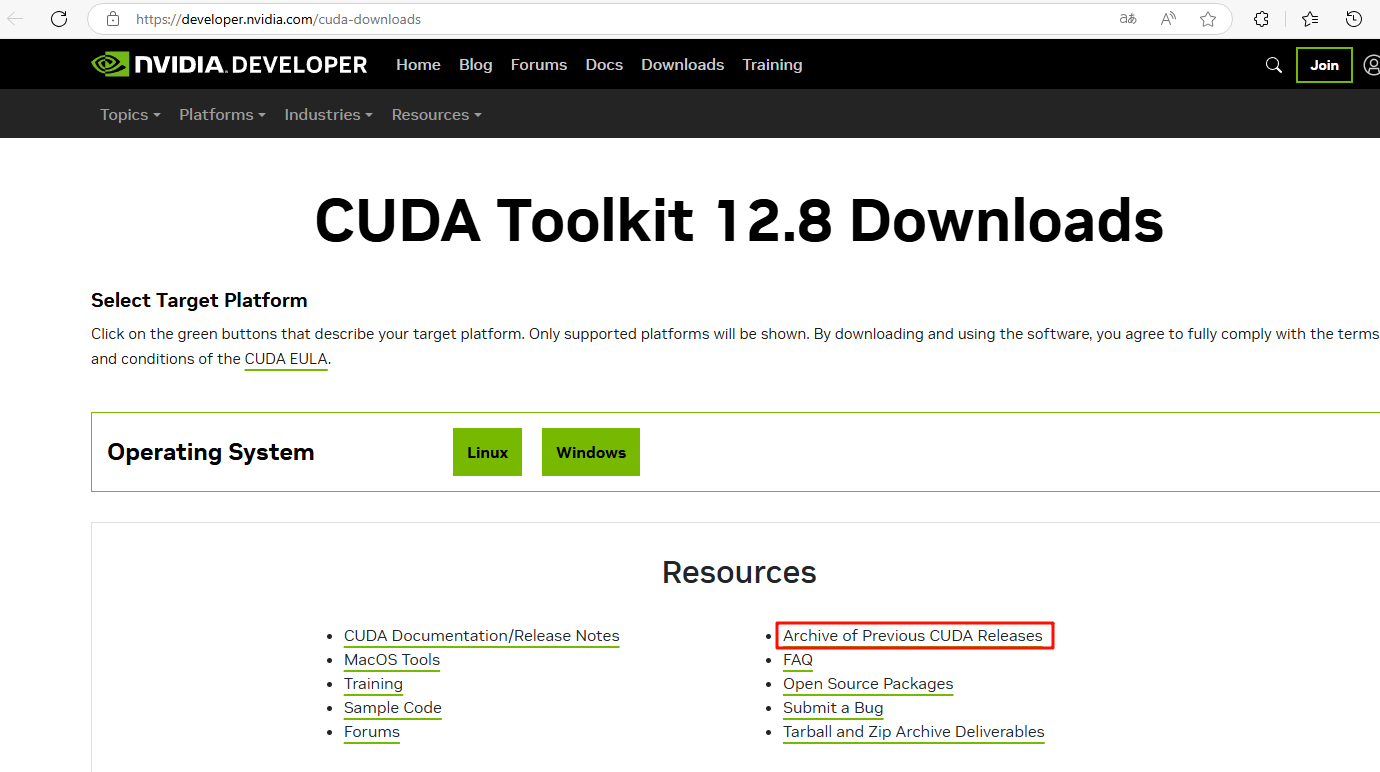

安装方式对比:
| 安装方式 | 描述 | 特点 | 适用场景 |
|---|---|---|---|
| deb(local) | 本地 .deb 包文件,包含了所有必要的 CUDA 组件 | - 不需要联网下载依赖 - 使用系统包管理工具(如 dpkg 或 apt)- 离线安装 | - 离线环境 - 网络不稳定的场景 |
| deb(network) | 配置 NVIDIA 的 APT 源进行安装 | - 在线安装,从 NVIDIA 服务器下载组件 - 支持自动更新 - 使用 apt 管理 | - 在线环境 - 希望保持 CUDA 最新版本 |
| runfile(local) | 独立的可执行文件,包含了所有 CUDA 的组件 | - 不依赖系统包管理工具 - 手动解决依赖 - 高度定制化安装 - 可以自定义安装路径 | - 系统中没有包管理工具(非 Debian/Ubuntu 系统) -需要在多用户环境中隔离 CUDA 环境 |
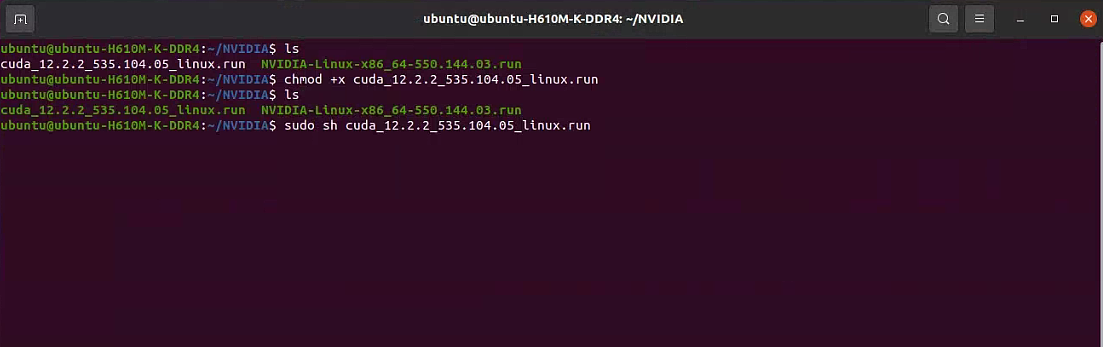
2. 安装CUDA(以runfile方式为例)
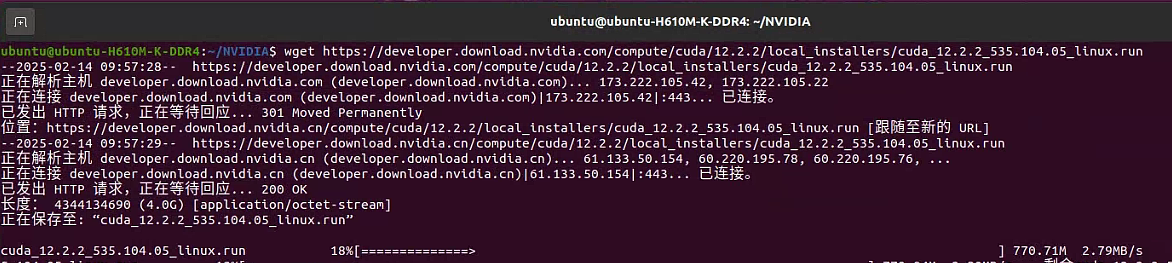
1 | wget https://developer.download.nvidia.com/compute/cuda/12.2.2/local_installers/cuda_12.2.2_535.104.05_linux.run |
安装过程:(回车后需要,等待片刻… )
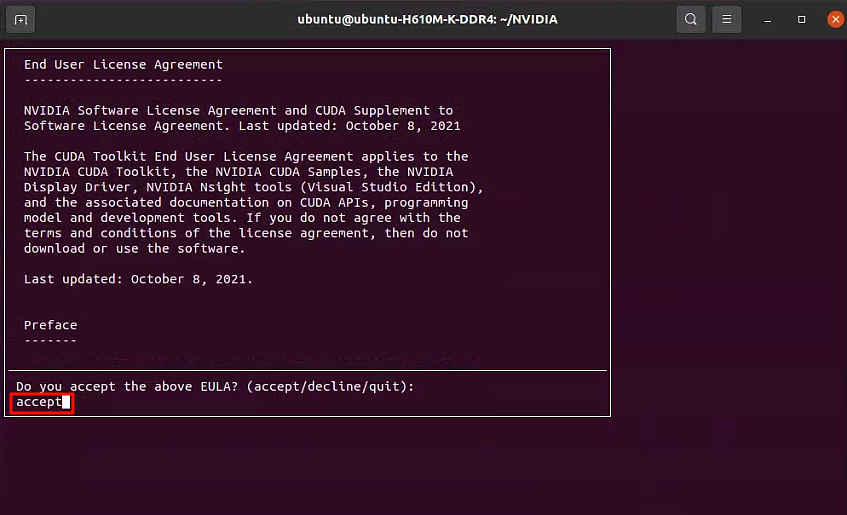
接受最终用户许可协议(输入“accept”)
回车键进行勾选,括号中显示X就是选中,没有X就是没有选中,上下键控制移动
⚠️取消勾选 “Driver” 安装选项,因为我们已经手动安装了最新版本的驱动
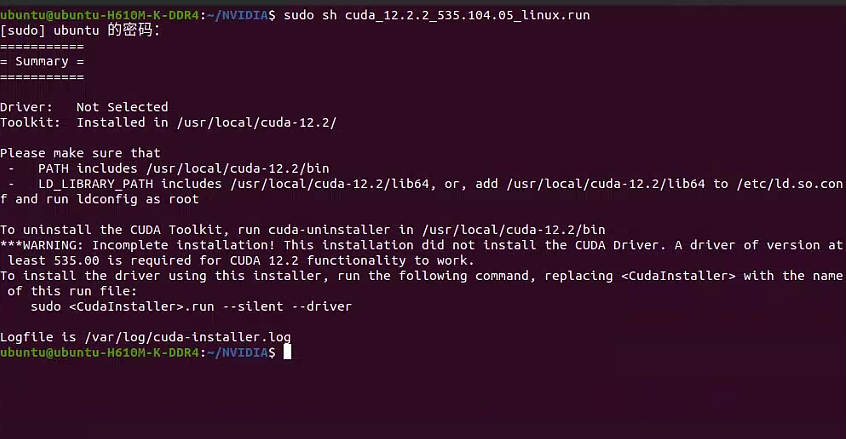
选择“Install”开始安装
等待安装完成
使用大模型解释一下:


3. 配置环境变量
将CUDA的路径添加到系统环境变量中
编辑~/.bashrc文件:
1 | nano ~/.bashrc |
在文件末尾添加以下行(请根据你的CUDA版本修改路径):
1 | export PATH=/usr/local/cuda-12.2/bin:$PATH |
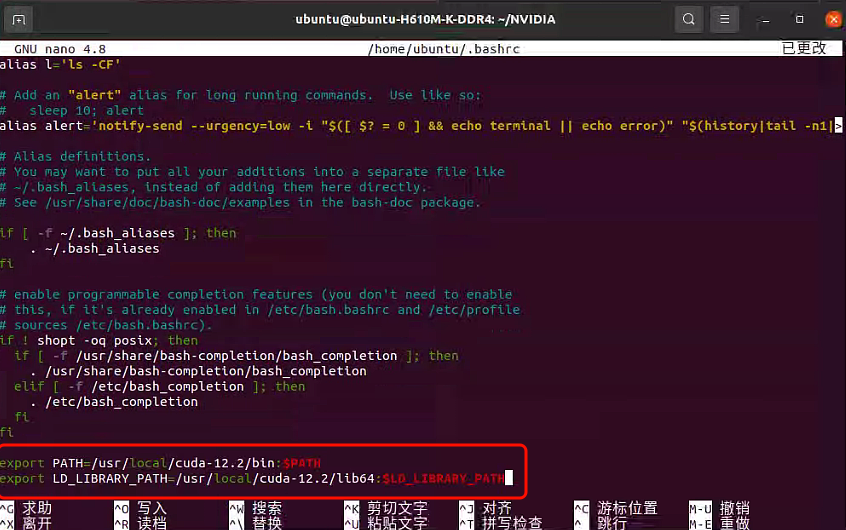
💡 建议:将 CUDA 路径放在
$PATH前面,确保优先使用指定版本。
环境变量配置方式对比:
| 对比维度 | 第一种写法(前置) | 第二种写法(后置) |
|---|---|---|
| 命令示例 | export PATH=/usr/local/cuda-12.2/bin:$PATH | export PATH=$PATH:/usr/local/cuda-12.2/bin |
| 路径添加顺序 | 将指定路径(如 /usr/local/cuda-12.2/bin)放在现有路径的前面 | 将指定路径追加到现有路径的后面。 |
| 优先级 | 系统会优先查找指定路径中的内容(如 CUDA 12.2 的工具和库 | 系统会优先查找现有路径中的内容,只有在现有路径中找不到时,才会查找指定路径的内容 |
| 适用场景 | - 明确指定使用某个版本的 CUDA 工具包 - 系统中存在多个版本的 CUDA 或相关工具时 | - 希望保留现有路径的优先级 - 系统中不存在其他版本的 CUDA 或相关工具时 |
| 优点 | - 避免因路径优先级问题导致冲突 - 确保使用指定版本的 CUDA 工具包 | - 不会影响现有路径的优先级 - 适合简单的单版本环境 |
| 缺点 | 如果指定路径中的工具或库有问题,可能会导致系统无法正常工作 | 如果现有路径中存在其他版本的工具或库,可能会导致使用旧版本的CUDA 工具 |
最终PATH示例 | /usr/local/cuda-12.2/bin:/usr/bin:/usr/local/sbin:... | /usr/bin:/usr/local/sbin:/usr/local/cuda-12.2/bin:... |
| 推荐使用场景 | 多版本共存、需要明确指定 CUDA 版本的场景 | 单版本环境、不需要更改现有路径优先级的场景 |
4. 使配置生效
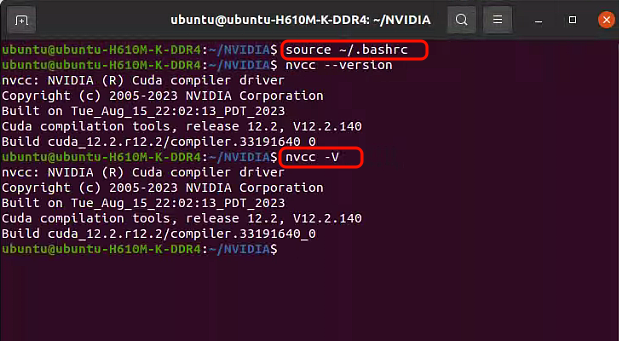
1 | source ~/.bashrc |
5. 验证 CUDA 安装
1 | nvcc --version |
如果显示CUDA编译器的版本信息,则安装成功。
安装cuDNN
cuDNN是NVIDIA专门为深度学习优化的库,显著提升了训练和推理速度
下载cuDNN
一般最新版本的显卡驱动都能适配最新版本的 cuDNN,若最新版本不适合当前的 CUDA,可以安装历史版本。
访问NVIDIA cuDNN下载官网,选择与CUDA版本兼容的cuDNN。
选择相应选项后会生成下载命令:
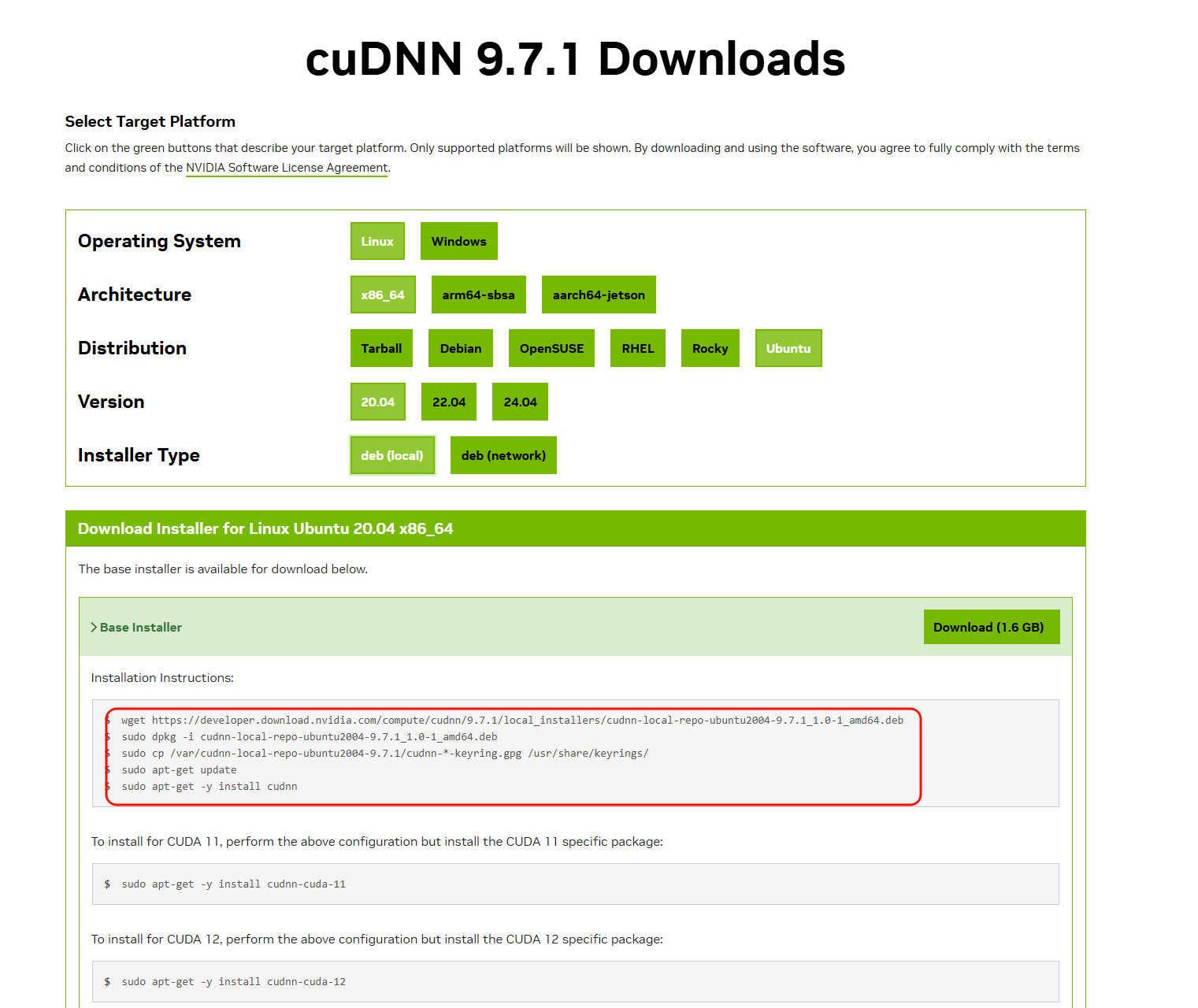
安装cuDNN
1 | wget https://developer.download.nvidia.com/compute/cudnn/9.7.1/local_installers/cudnn-local-repo-ubuntu2004-9.7.1_1.0-1_amd64.deb |
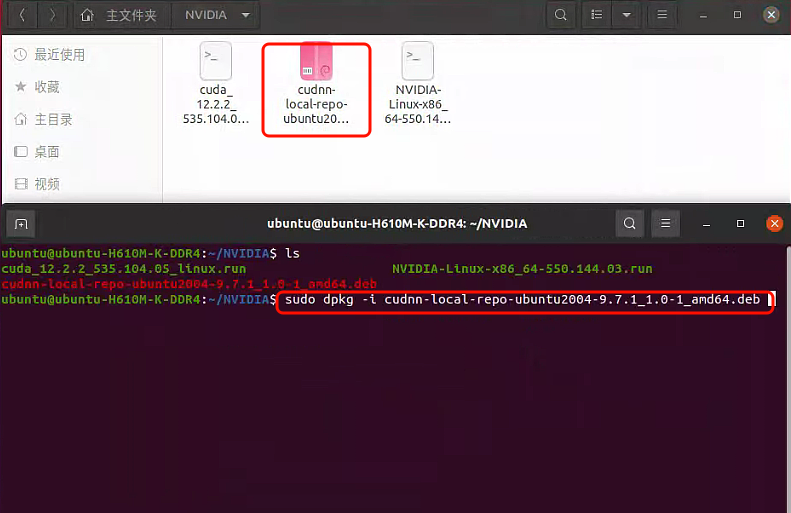
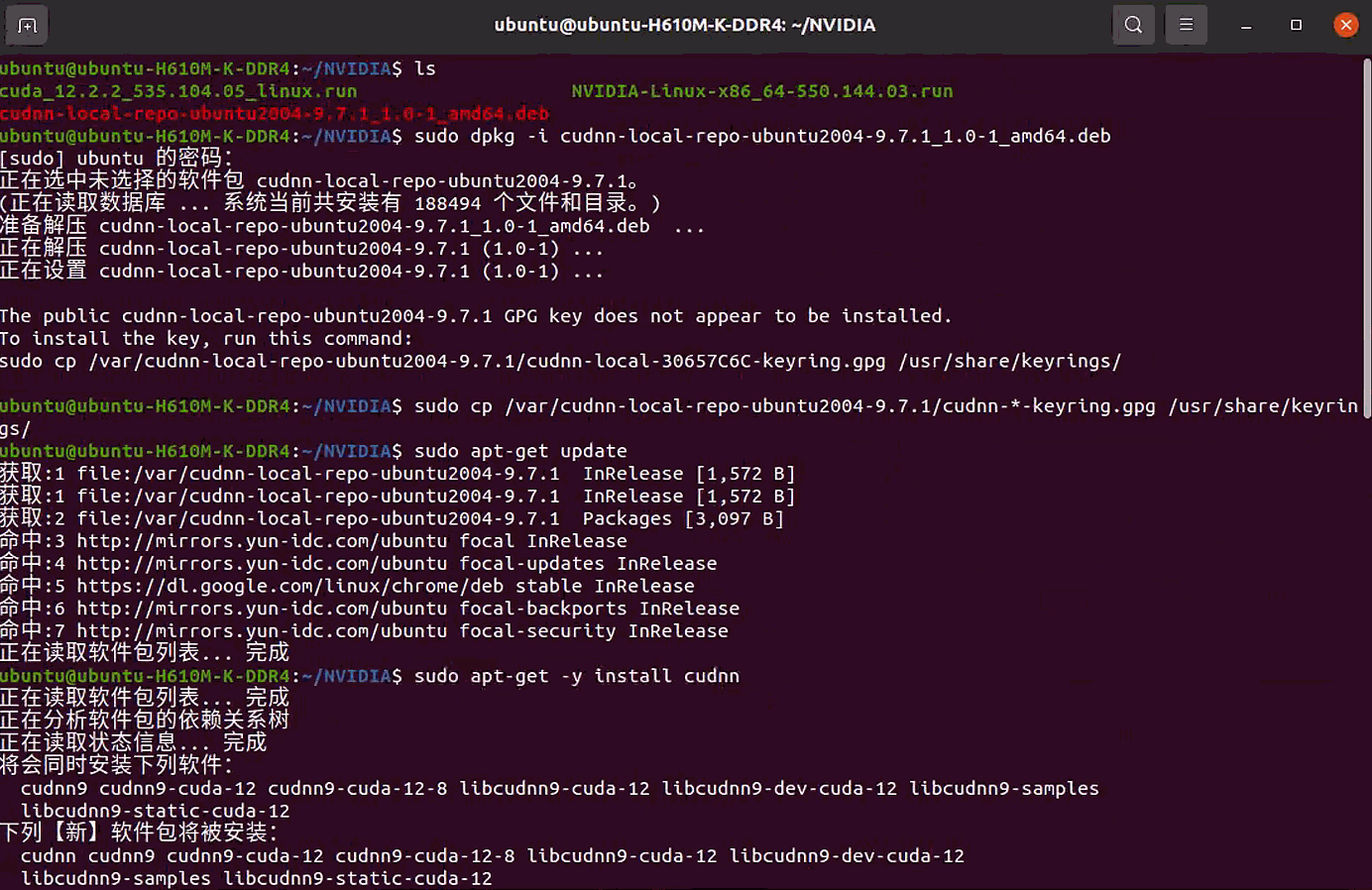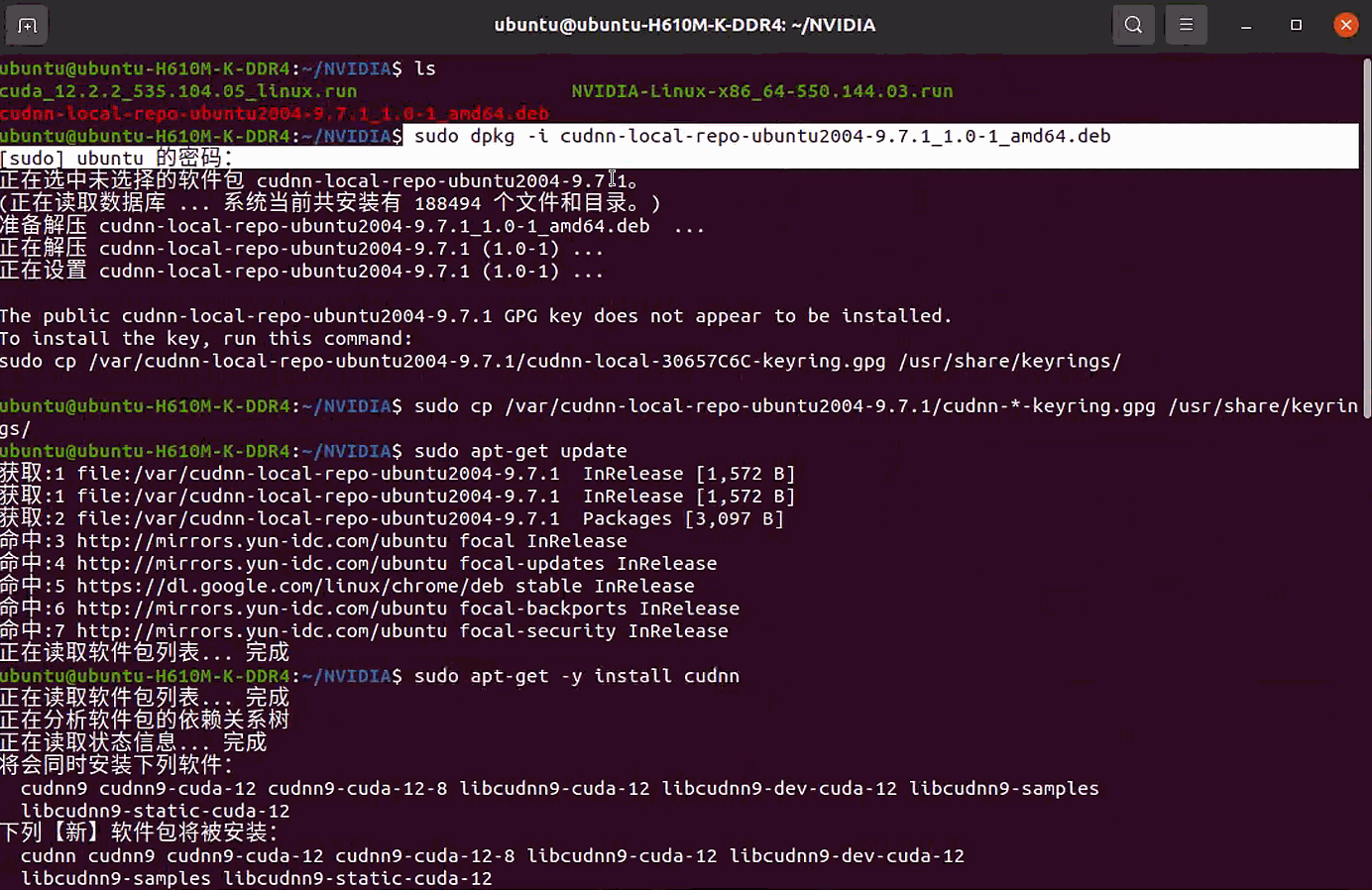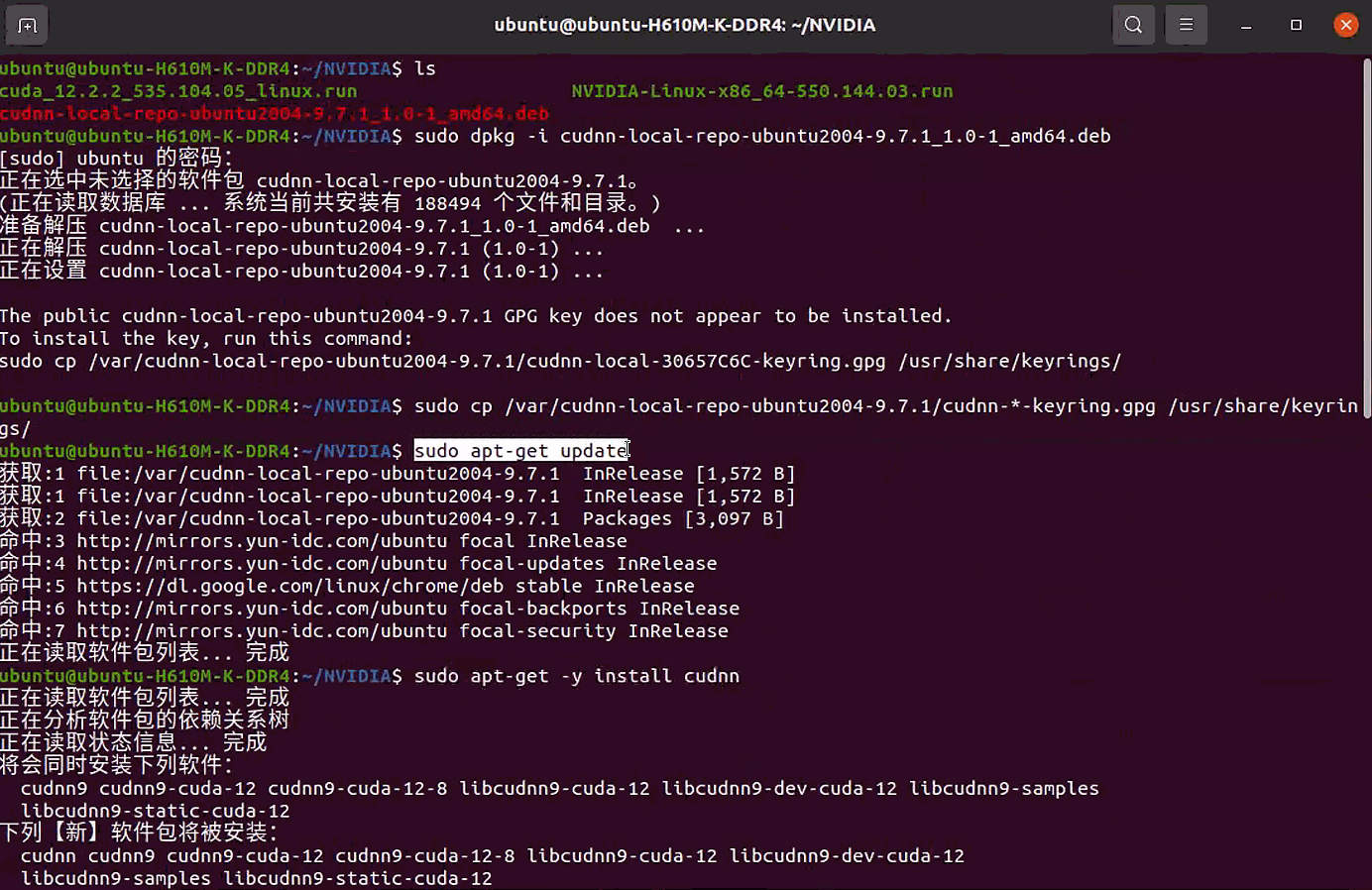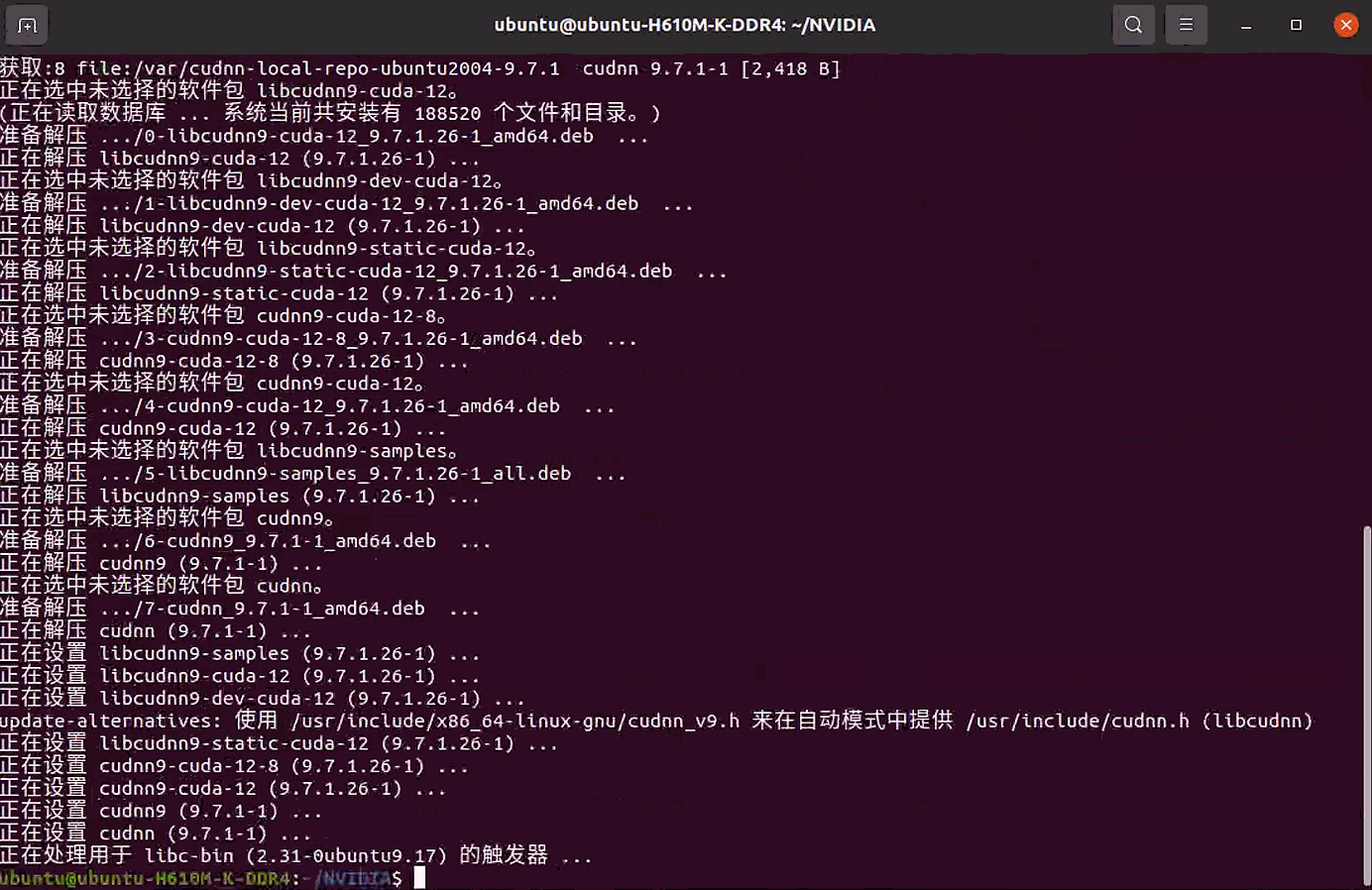
验证 cuDNN
无直接命令,后续通过 PyTorch 可验证。
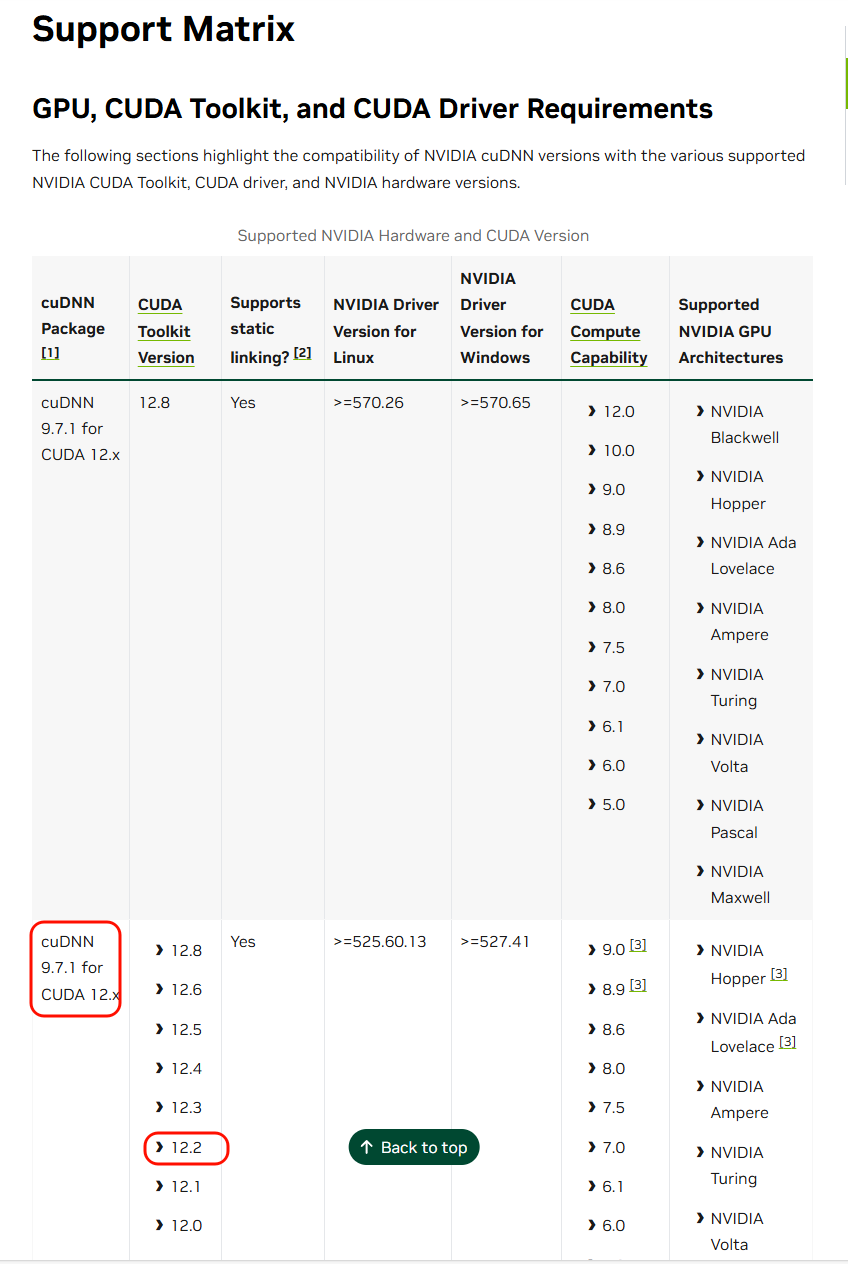
版本兼容性查询:
查看Support Matrix确认支持的CUDA版本
如不支持最新版本,可查找
cuDNN支持的历史版本
管理Python环境并安装Miniconda
深度学习项目通常需要特定的Python版本,多项目版本会发生冲突,建议使用环境管理工具。
为了避免不同项目之间的包冲突,强烈建议使用虚拟环境。Miniconda是一个轻量级的Conda发行版,非常适合管理环境和包。
直接安装指定版本Python(不推荐)
0. 检查当前已安装的 Python 版本
运行以下命令查看系统中已安装的 Python 版本:
1 | python3 --version |
安装特定版本的 Python,跳过此步骤
1. 更新系统软件包
在安装任何新软件之前,确保系统的软件包列表是最新的:
1 | sudo apt update # 更新软件包列表 |
2. 添加deadsnakes PPA(可选)
Ubuntu 的默认软件源可能不包含所有 Python 版本。为了安装更广泛的 Python 版本,可以使用
deadsnakesPPA(Personal Package Archive)。运行以下命令添加该 PPA:
1 | sudo add-apt-repository ppa:deadsnakes/ppa # 导入 Python 的稳定版 PPA |
3. 安装指定Python版本
例如想安装 Python 3.10,可以运行以下命令:
1 | sudo apt install python3.10 |
如果想安装其他版本,只需将版本号替换为所需的版本即可
4. 验证安装
安装完成后,验证指定版本的 Python 是否成功安装
1 | python3.10 --version |
5. 设置默认版本(可选)
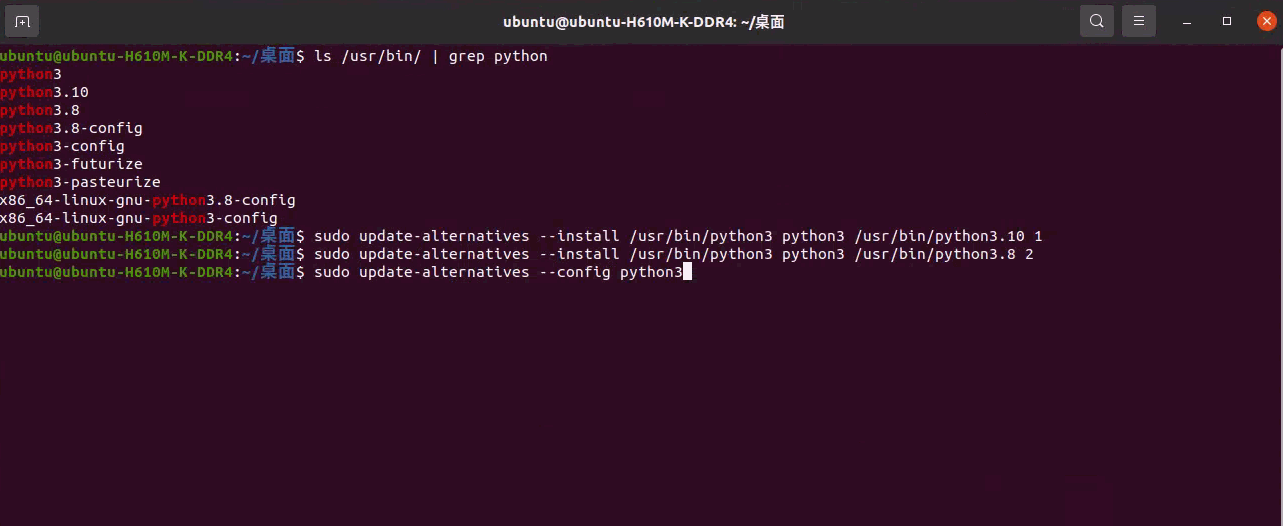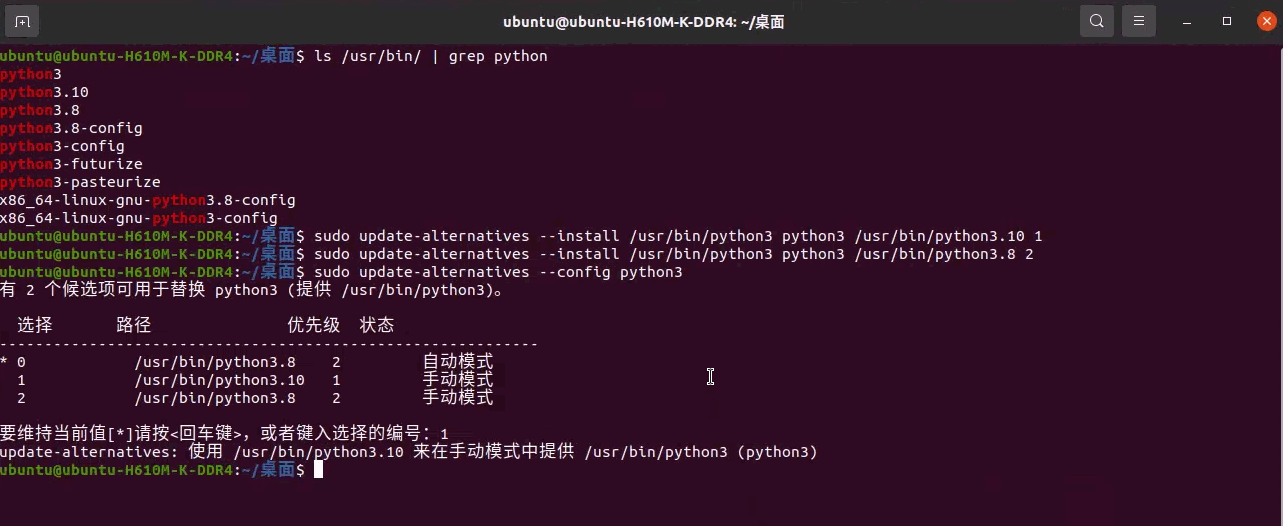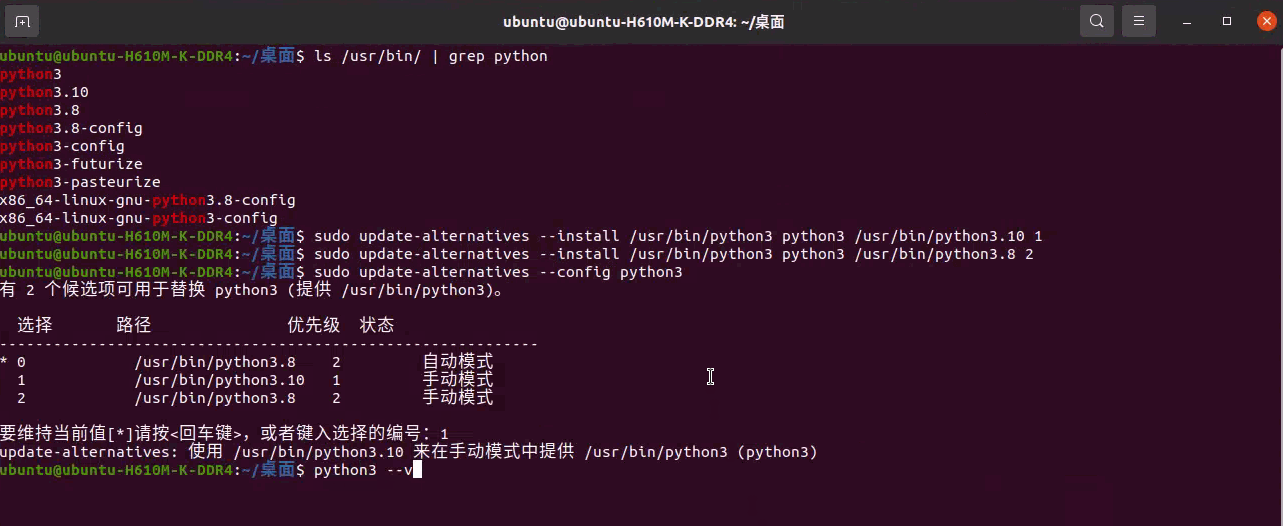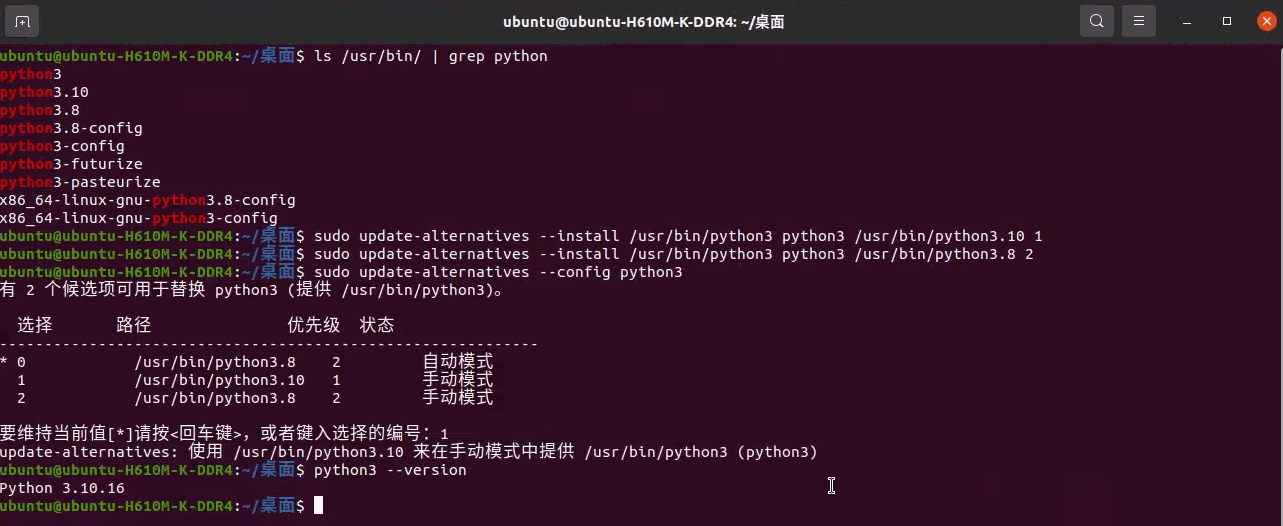
如果希望将新安装的 Python 版本设置为默认版本,可以使用 update-alternatives 工具来管理多个 Python 版本
添加 Python 版本到 update-alternatives:
1 | sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.10 1 |
每条命令末尾的数字(即 1、2、3 等)表示该版本的优先级。数值越大,优先级越高。
查看当前的 update-alternatives 配置
1 | sudo update-alternatives --display python3 |
删除添加的 Python 版本
1 | sudo update-alternatives --remove python3 /usr/bin/python3.8 |
配置默认版本:
执行以下命令,列出系统上已安装的所有 Python 版本,默认版本的编号旁边会标有星号「*」:
1 | sudo update-alternatives --config python3 |
输入 Python 版本旁边的编号,即可将其设置为默认版本。
使用软链接设置默认 Python 版本:
1 | sudo rm /usr/bin/python3 |
6. 安装 pip
自动安装 Python 3 的包管理工具 pip
1 | sudo apt install python3-pip |
某些情况下,安装指定版本的 Python 后可能需要手动安装 pip。可以使用以下命令安装对应版本的 pip:
1 | sudo apt install python3.10-distutils |
安装完成后,建议升级 pip 到最新版本:
1 | pip3 install --upgrade pip |
注意事项
避免覆盖系统默认 Python
Ubuntu 系统依赖于默认的 Python 版本(通常是 Python 3.x)。不要直接修改/usr/bin/python或/usr/bin/python3,否则可能导致系统工具无法正常工作。从源码编译安装(高级用户)
如果需要安装非常新的 Python 版本(例如开发版),可以从 Python 官方网站 下载源码并编译安装。- 虚拟环境推荐
如果需要同时使用多个 Python 版本,还是建议使用venv或pyenv创建隔离的虚拟环境,以避免版本冲突。
Python版本管理工具对比
| 工具名称 | 类型 | 功能描述 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| venv | Python 内置虚拟环境工具 | 为每个项目创建独立的 Python 环境,隔离依赖包。 | - 轻量级 - 内置工具,无需额外安装 - 简单易用 | - 仅支持 Python 包管理 - 不支持跨语言包管理 | 小型 Python 项目,需要隔离不同项目的依赖。 |
| pyenv | Python 版本管理工具 | 管理多个 Python 版本,允许用户快速切换不同版本的 Python。 | - 支持多版本 Python 安装与切换 - 不影响系统默认 Python - 常与其他工具(如 pyenv-virtualenv)结合使用 | - 需要手动安装 - 对初学者可能稍显复杂 | 开发者需要频繁切换 Python 版本或维护多个版本的项目。 |
| conda | 通用包管理系统 | 构建和管理多种语言(不仅限于 Python),同时支持环境管理(类似 pip + venv)。 | - 支持跨语言包管理 - 强大的环境管理功能 - 自动解决依赖冲突 | - 较重,占用更多磁盘空间 - 可能与 pip 存在兼容性问题 | 数据科学、机器学习等需要复杂依赖管理的项目。 |
| Miniconda | Conda 的轻量版 | 包含 Conda 核心功能和 Python,不包含其他预装库,适合对磁盘空间要求严格的用户。 | - 轻量级 - 提供 Conda 的核心功能 - 用户可以按需安装所需库 | - 初次使用需要手动安装常用库 - 对新手不够友好 | 数据科学家或开发者需要灵活控制环境和依赖,但不想安装臃肿的 Anaconda。 |
| Anaconda | 数据科学平台 | 包含 Conda、Python 以及大量预装的科学计算和数据分析库(如 NumPy、Pandas、Matplotlib 等)。 | - 开箱即用,预装大量常用库 - 适合数据科学和机器学习 - 强大的环境管理功能 | - 占用大量磁盘空间(数 GB) - 对于不需要预装库的用户来说过于臃肿 | 数据科学、机器学习、深度学习等需要大量科学计算库的项目。 |
安装Miniconda(推荐)
1. 下载安装脚本
(1) 访问 Miniconda 官方网站
Miniconda 的安装脚本可以从其官方网站下载:

(2) 选择合适的版本
根据你的操作系统(Linux、macOS 或 Windows)和系统架构(x86_64 或 ARM),选择对应的安装脚本。例如:
我这里是Linux系统x86_64架构,选择下载 Miniconda3-latest-Linux-x86_64.sh。
(3) 使用命令行下载(可选)
如果你在终端中操作,可以直接使用 wget 或 curl 下载安装脚本。例如:
1 | wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh |
或者:
1 | curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh |
2. 安装Miniconda
(1) 赋予脚本执行权限
确保下载的脚本具有可执行权限:
1 | chmod +x Miniconda3-latest-Linux-x86_64.sh |
(2) 启动安装程序
运行安装脚本:
1 | ./Miniconda3-latest-Linux-x86_64.sh |
(3) 按照提示完成安装
安装过程中会提示你进行以下操作:
阅读并接受许可协议:
- 按下
Enter键滚动查看许可协议内容。 - 输入
yes接受许可协议。
- 按下
选择安装路径:
- 默认安装路径是用户的主目录下的
miniconda3文件夹(例如/home/username/miniconda3)。 - 如果需要自定义路径,可以手动输入新的路径。
- 默认安装路径是用户的主目录下的
是否初始化 Miniconda:
- 安装程序会询问是否将 Miniconda 初始化到当前 shell 配置文件(如
.bashrc或.zshrc)。 - 输入
yes将自动配置环境变量,使conda命令可用。
- 安装程序会询问是否将 Miniconda 初始化到当前 shell 配置文件(如
激活 Miniconda 环境,使其配置生效:
通过以下命令来让 Miniconda 的相关设置(如环境变量等)在当前终端会话中生效,以便能够正常使用 Miniconda 提供的各种功能1
source ~/miniconda3/bin/activate
初始化Conda,使其能够在所有可用的 shell (如 bash、zsh 等)中正常工作:
conda init 命令会根据指定的 shell 类型,对相应的 shell 配置文件(如 .bashrc、.zshrc 等)进行修改,添加必要的配置项(如环境变量设置等)。—all 参数表示对所有可用的 shell 进行初始化操作。
1
conda init --all
3. 验证安装
(1) 检查 conda 是否可用
重新启动终端或运行以下命令以加载新的环境变量:
1 | source ~/.bashrc |
然后检查 conda 是否正常工作:
1 | conda --version |
如果输出类似以下内容,则说明安装成功:
1 | conda 24.11.2 |
(2) 测试基本功能
创建一个新的 Conda 环境安装PyTorch:
1 | conda create -n pytorch_env python=3.10 |
激活环境:
1 | conda activate pytorch_env |
验证 Python 版本:
1 | python --version |
4. 更新 Conda(可选)
为了确保 Conda 是最新版本,可以运行以下命令更新:
1 | conda update conda |
5. 卸载 Miniconda(可选)
如果你决定不再使用 Miniconda,可以通过以下步骤卸载:
(1) 删除安装目录
删除 Miniconda 的安装目录。例如:
1 | rm -rf ~/miniconda3 |
(2) 清理环境变量
编辑你的 shell 配置文件(如 ~/.bashrc 或 ~/.zshrc),删除与 Miniconda 相关的行。例如:
1 | # >>> conda initialize >>> |
删除上述代码块后保存文件,并重新加载配置:
1 | source ~/.bashrc |
6. 使用国内镜像加速(可选)
如果你在中国大陆,可以使用国内镜像源加速 Conda 的包管理。例如,使用清华大学的镜像源:
1 | conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ |
PyTorch安装与 GPU 验证
在激活的Conda环境中安装PyTorch
安装PyTorch
访问PyTorch官网: 前往 PyTorch官网安装页面。
选择配置: 根据你的系统和CUDA版本选择合适的安装选项。
cu121表示支持 CUDA 12.1 的 PyTorch 版本。torch是 PyTorch 的核心库。torchvision和torchaudio是 PyTorch 的扩展库,分别用于计算机视觉和音频处理。
注意:即使系统安装的是 CUDA 12.2,PyTorch 官方尚未支持 CUDA 12.2,也可以尝试安装支持 CUDA 12.1 或 CUDA 11.8 的pytorch版本,因为向下兼容
CUDA 12.1版本
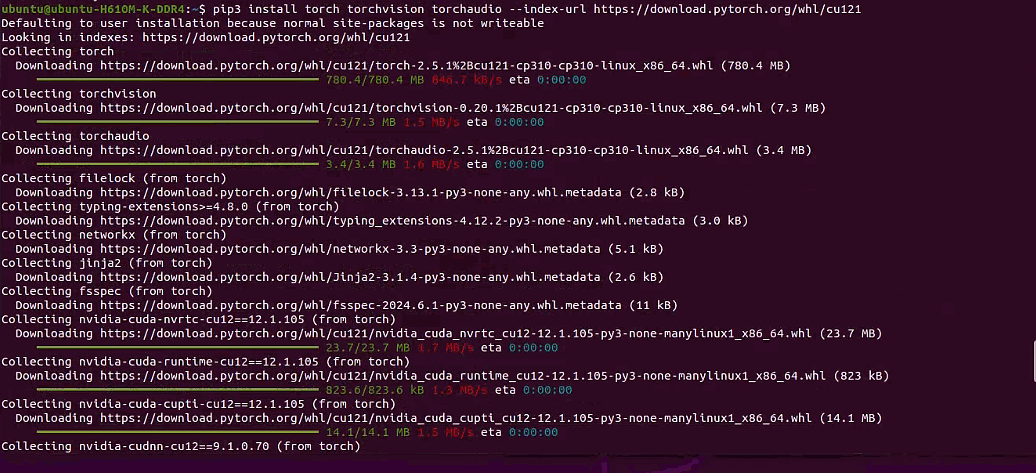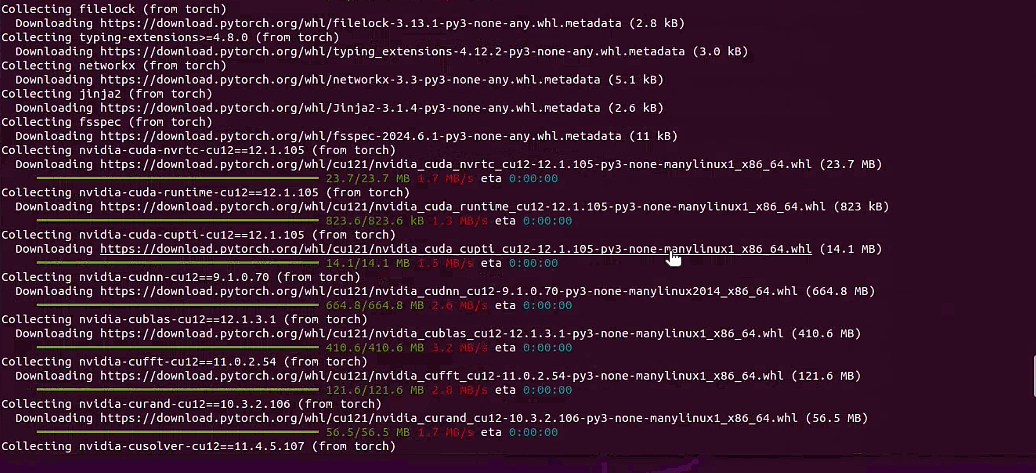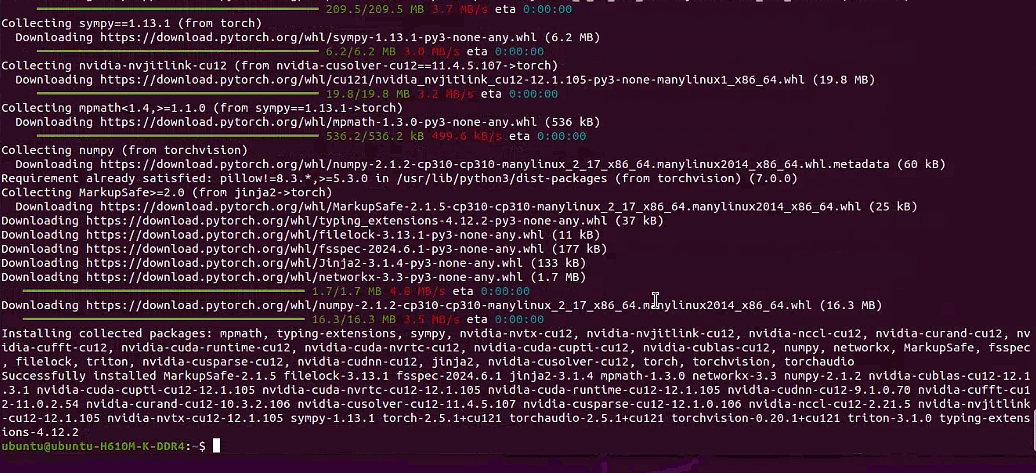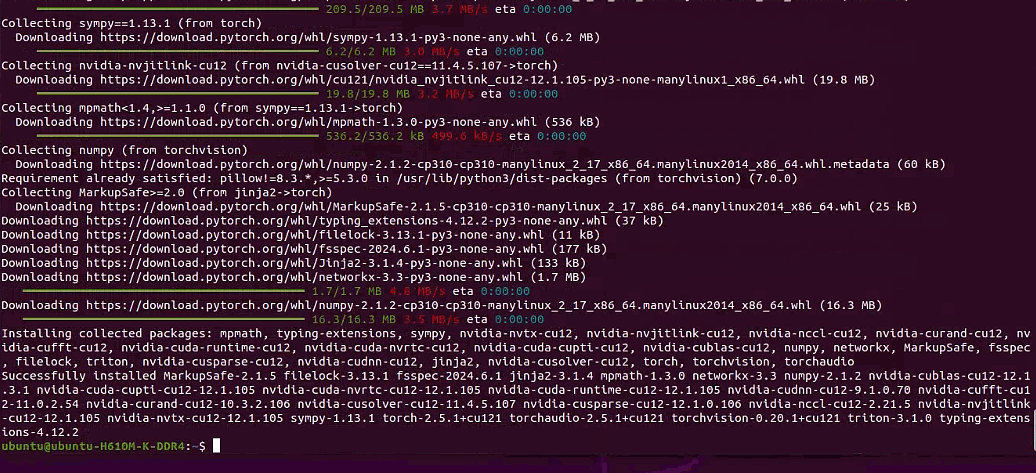
1 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 |
CUDA 11.8版本
1 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 |
CPU版本(测试用)
如果暂时不需要 GPU 支持,可以安装仅支持 CPU 的 PyTorch 版本
1 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu |
使用国内镜像源
如果网络连接不稳定导致安装失败或超时,可以尝试使用国内镜像源(如清华源)来加速下载
1 | pip3 install torch torchvision torchaudio --index-url https://mirrors.tuna.tsinghua.edu.cn/pytorch-wheels/cu121 |
权限问题
如果遇到权限问题,可以尝试加上
--user参数:1
pip3 install torch torchvision torchaudio --user
手动下载
如果上述方法均无效,您可以手动下载 PyTorch 的 .whl 文件并安装。访问 PyTorch 官方网站 或 PyTorch 下载页面,选择适合您环境的 .whl 文件并使用以下命令安装:
1 | pip3 install /path/to/downloaded/file.whl |
验证安装
在 Python 环境中,创建测试脚本验证CUDA和cuDNN是否正常工作:
如果输出显示
CUDA Available: True以及cuDNN Available: True,则说明 CUDA 和 cuDNN 已成功安装并可供使用。
1 | import torch # 导入 PyTorch 库 |
输出:

🎉 恭喜你! 你的深度学习环境已成功搭建!
总结
本文详细介绍了Ubuntu系统下NVIDIA显卡驱动与CUDA环境的完整配置流程。关键要点包括:
- 安装顺序:显卡驱动 → CUDA → cuDNN → 深度学习框架。
- 版本兼容:确保各组件版本相互匹配,是成功的关键。
- 环境隔离:使用Conda等工具管理Python环境,避免依赖冲突。
- 验证闭环:每一步安装后都进行验证,及时发现并解决问题。
- 掌握排错方法:
nouveau冲突和Secure Boot问题是两大常见障碍。
如有疑问,欢迎留言交流!
觉得有用?请点赞、收藏、分享给更多需要的人!
官方文档与参考资源
官方核心链接
- NVIDIA驱动下载: https://www.nvidia.com/Download/index.aspx
- CUDA Toolkit历史版本下载: https://developer.nvidia.com/cuda-toolkit-archive
- cuDNN历史版本下载: https://developer.nvidia.com/rdp/cudnn-archive
- PyTorch官网安装向导: https://pytorch.org/get-started/locally/
- Miniconda官方文档: https://docs.conda.io/en/latest/miniconda.html
硬件信息查询
- PCI ID Repository: https://pci-ids.ucw.cz/
- TechPowerUp GPU Database: https://www.techpowerup.com/gpu-specs/
社区参考文章
本文基于Ubuntu 24.04 LTS系统编写,其他版本可能存在细微差异,请根据实际情况调整。